
This sample Differences-In-Differences In Approaches Research Paper is published for educational and informational purposes only. If you need help writing your assignment, please use our research paper writing service and buy a paper on any topic at affordable price. Also check our tips on how to write a research paper, see the lists of criminal justice research paper topics, and browse research paper examples.
Overview
Although almost universally acknowledged as the most powerful research design for causal attribution, the randomized control trial (RCT) is not without limitations in applied research settings. Foremost among those limitations is the generalizability of study findings due to vicissitudes in tested sample, setting, intervention, and result. If generalizability cannot be assumed, the value of the finding as evidence for future action may be tempered.
In addition, several practical and theoretical limitations may be imposed by the RCT. Probabilistic equivalence on all measured and unmeasured characteristics is difficult to assume in many applied settings. The ethical requirement of clinical equipoise for many interventions mathematically limits discovery of effective interventions to 25–50 % of trials. RCT research tends to produce evidence on which recipients respond to the intervention being tested and not produce evidence on the intervention characteristics responsible for that response.
The preference for RCTs may bias what interventions are studied and what evidence is considered. Many interventions are not amenable to randomization, and evidence of their effectiveness may be discounted if only evidence from RCTs is valued. If only RCTs are valued, the increasingly available archival and electronic records data is similarly discounted as a source of evidence of what works as randomization must occur prior to intervention. Finally, as a design for causal proof, RCTs tend to focus solely on program effectiveness and not on other considerations of implementation and maintenance; as a prospective design, with measures often established prior to the research being conducted, it may be a design ill-suited to observing and documenting unintended consequences.
Two additional limitations result from a hyper-allegiance to RCTs for evidence. When RCTs are applied in real-world settings, they often assess the links between complex interventions and the individual mediators and moderators of distal outcomes using complex statistical models and multivariate methods. Including such findings in formal meta-analyses is difficult and undermines the accumulation of evidence. Also reducing the accumulation of evidence is the limited number of researchers qualified to conduct formal RCTs.
To supplement the evidence available for evidence-based practice, an effectiveness-surveillance system using a synthetic difference-in-differences design is proposed. Such a system would provide associational evidence of effectiveness and provide a valuable complement to the evidence generated by RCTs.
The RCT: A Powerful Design For Cause
In an ideal world, or the idealized world of the laboratory study, it is difficult to argue against the logic of the RCT for drawing causal inferences. In its simplest form, a sufficient number of units (typically individuals) are selected to be representative of a known population and are randomly assigned to either a treatment or a control condition. Those in the treatment condition are then exposed to a stimulus (also known as the manipuland, independent variable, treatment, or intervention) that is withheld from those in the control condition. Under the logic of the design, the performance of the control group approximates what would have been the performance of the experimental group in the absence of the stimulus being tested. Since the experimental group cannot simultaneously both receive and not receive the stimulus, scientists rely on inference to attribute differences in performance to the presence and absence of the stimulus being tested. If, in a well-controlled trial, the outcome covaries with the presence and absence of the stimulus, then a causal relationship is generally inferred.
Since first proposed in its modern form by Sir Austin Bradford Hill (1952), the RCT as the premiere method of causal inquiry has grown in both importance and stature. RCTs reside below systematic review and meta-analysis at the peak of evidence-based medicine’s evidence pyramids and have been granted priority by the Department of Education (Scientifically-based evaluation methods 2003). Well-implemented randomization creates two groups with “initial probabilistic equivalence,” that is, “groups that are comparable to each other within the known limits of sampling error” (Cook and Campbell 1979, p. 341). This, in turn, allows the researcher to assume that differences in outcome are attributable entirely to the intervention and are not influenced (confounded) by preexisting subject characteristics. Moreover, if the sample prior to randomization is representative of a population, randomization allows the result of an RCT to be generalized to the population represented by the sample.
While the RCT is a powerful strategy for attributing cause in many research settings and has been effectively applied to answer many important research questions, it is merely one feature of a well-designed experiment. In and of itself, randomization does not ensure valid or reliable findings nor ensure inferences based on those findings are correct. Well-conducted randomization creates covariate-balanced groups equal in their probability of displaying the outcome(s) of interest and differing only in their receipt or nonreceipt of the treatment/intervention/stimulus being tested. What randomization does not control for are other vicissitudes of the research endeavor. These can include sample selection; research methods and procedures; the use of sensitive, reliable, and valid measures; application of appropriate statistics; appropriate interpretation of findings and their limitations; and, finally, complete and accurate reporting of the study and possible threats to the validity of the research findings, as discussed in detail elsewhere (e.g., Cook and Campbell 1979; Lipsey and Cordray 2000; Shadish et al. 2002). In other words, when applied to real-world research in real-world settings, unequivocal belief that in and of itself randomization is sufficient to produce credible evidence is not tenable.
Before accepting a knowledge claim resulting from an RCT (or any other evidence claim, for that matter), all aspects of the study design and execution must be examined and judged. As an exercise in applied logic, all parts of the research endeavor work together to form a conclusion. The result produced from a single well-conducted RCT has tremendous value and, arguably, no other single study design produces evidence of equal merit. However, the intrinsic value of the RCT design for generating knowledge should not be confused with the extrinsic value of the design for generating actionable knowledge (i.e., its capacity to document “worth”). Moreover, its elevation to the “the gold standard” for knowledge generation has had the unintended consequence of discounting other methods of inquiry (Gugiu and Gugiu 2010). The discussion that follows provides several potential, practical, and documented limitations of relying on RCTs for generating robust actionable knowledge in criminology and criminal justice, with some of these limitations also applying to quasiexperiments. This research paper concludes by offering an alternative design for knowledge accretion that may produce evidence of sufficient merit and worth to meet the expanding need for evidence of effectiveness of what works, for whom, and under what conditions. In providing this perspective, we add to the already robust literature documenting the limitations of RCTs (e.g., Boruch 1975; Pawson 1994).
Key Issues/Controversies
In this section we discuss some of the key issues which may limit the extrinsic value of the RCT for creating actionable knowledge. After a brief introduction on the lack of standards for assessing external validity and generalizability, potential limitations of different aspects of the RCT for creating generalizable evidence are discussed. The section closes with brief discussions of a number of practical and theoretical limitations of relying on the RCT for knowledge generation.
Lack Of Standards For Assessing Generalizability
Through its control of confounds, a sufficiently large and well-implemented RCT undoubtedly provides greater internal validity and better warrant for attributing results to the intervention tested than do other study designs. Moreover, there are clear standards for evaluating study quality, and these standards allow us to judge the internal validity of the knowledge claimed by the trial. However, the purpose of science is the identification of generalizable conclusions (Overton 1998), and “conclusions limited to a specific subset .. . are not scientifically informative” (Hunter and Schmidt 2000, p. 277). External validity estimates the extent to which the results obtained by a study generalize to an unstudied population; if subjects in an RCT are representative of the unstudied population, study results are likely to replicate well in these unstudied populations. Unfortunately, there are few established guidelines for estimating external validity (Rothwell 2005) and, as estimated in the social sciences, what guidelines do exist often seem reduced to simple sample demographics. In contrast, Rothwell postulates 39 issues that potentially affect external validity for clinicians to consider when evaluating clinical practice RCTs in medicine.
Potential Limitations Of Generalizability
Below we discuss several potential limitations of generalizability in an RCT, particularly those that are designed to produce evidence of efficacy. These concerns, in particular, have been proposed as central to the failure of efficacy research to translate into effective behavioral and health promotion efforts (Glasgow et al. 2003). These limitations relate to generalizability of the sample, the setting, the intervention itself, and the result.
Generalizability of the Sample. How representative of unstudied populations are subjects who agree to participate in an RCT? For many practical reasons, study populations are likely selected on their proximity to research staff. If researchintensive settings (e.g., university towns) are fundamentally different from other settings, it may limit generalizability. Subjects in such settings, and those who participate in research generally, are likely more motivated to seek intervention than those not interested in participating and are willing to be randomized to a control condition in which they will receive no, limited, or delayed services. This willingness is ensured through the informed consent procedure, in which subjects voluntarily sign a plain-language form attesting to the fact that they understand the implications of participation. For many interventions this may not be problematic, but for efficacy research in which the sample is self-selected, homogeneous, highly motivated, and screened to control for comorbid conditions, it is reasonable to question the generalizability of the sample and if it is, in fact, representative of the population it claims to represent.
Generalizability of the Setting. In addition to much research being conducted in settings convenient to the researchers, it should be observed that all interventions occur within a political, economic, social, and cultural context. RCTs can be very effective at controlling these potential confounds within a study, but ignoring these external community-level characteristics when generalizing beyond the studied sample may ignore consequential causal factors. Simply put, even if demographic characteristics of the sample included in the RCT are similar to an unstudied population, generalizability will be compromised to the extent individual responsiveness to intervention is influenced by the political, economic, social, and cultural context of the community in which the intervention is tested relative to the community to which the findings are hoped to generalize. Since variance is often controlled by limiting an RCT to one particular setting, such trials provide no way of estimating if or how the unique circumstances of that setting influenced results. These potential influences are rarely discussed in the limitations sections of articles, and their consequence is likely unappreciated in federal initiatives that require implementation of science-based programs whose efficacy may have been established in a limited setting.
Generalizability of the Tested Intervention. Randomization controls for confounding by preexisting subject characteristics, but other factors associated with implementing and delivering the intervention can bias and limit the generalizability of a result. RCTs are often used to test whether an intervention is efficacious (is it effective under optimal conditions?); whether the intervention is effective under real-world conditions is an entirely different question. Often the intervention tested by an RCT is not the intervention that gets disseminated or adopted; developers often refine their interventions based on the results of their research, and even simple interventions are amalgams of activities that are typically adapted to local conditions (Durlak and DuPre 2008). If the intervention being implemented lacks fidelity to the intervention that was tested, the implemented intervention cannot be considered evidence-based.
Generalizability of the Result. The effect of a given cause is captured by the findings of a well-conducted RCT. Since findings are based on a comparison of outcomes in each arm of the experiment (e.g., a t-test that compares the means and standard deviations of each condition), each arm contributes equally to the observed finding. A fundamental implication of this assertion is that both conditions of an experiment must be fully specified (Reichardt 2011). Only if both arms of the experiment are fully understood and explicated can the results of an RCT be interpreted. This counterfactual definition of effect is known as the Rubin model of causality (Rubin 2005) and is integral to experimental design. Unfortunately, one seldom reads even a cursory description of what services were received by the counterfactual sample.
Although reliable statistics are lacking, it is likely that many RCTs in applied settings are corrupted by compensatory services within the comparison group. For example, a multisite randomized control study for high-risk youth (HRY) found that 21 of the 46 randomly assigned “control” sites (45.7 %) received more prevention services than the sites randomized to receive the HRY intervention. An initial analysis concluded that the HRY intervention had no effect, whereas statistically controlling for compensatory exposure disclosed a strong and significant positive effect (Derzon et al. 2005). Depending on which counterfactual is assumed, both results are arguably correct (the intervention was ineffective relative to other services available and more effective than not receiving prevention services). Note that if compensatory services had not been measured, an incorrect conclusion could have been that the intervention was not effective. If the counterfactual is not defined and not documented as carefully as the intervention, it is hard to imagine how the result of an RCT can be understood.
Practical And Theoretical Limitations To The RCT
Practical and theoretical limitations to the RCT are discussed below. These include assuming initial probabilistic equivalence, clinical equipoise, decisions about what evidence is considered, and limitations to knowledge accretion.
Assuming Initial Probabilistic Equivalence. Recall that the purpose of randomization is to create initial probabilistic equivalence. This is an idea that is closely tied to the theory of the intervention, its assumed causal relationship with the outcome, and the potential for other factors to produce the outcome or that influence subjects’ response to the intervention. As subject variability in response increases, confidence intervals tend to increase and commensurately larger samples are necessary for statistical power and avoiding a type II error (not finding an effect for interventions that are, in fact, effective). Thus, for interventions in which measures are robust and the causal relationship is mechanistic and deterministic and the effect is produced only by the cause being tested, the assumption of initial probabilistic equivalence may be strongly supported. However, if there are multiple sufficient causes to produce the outcome (over-determination), or if the theory and measures used account for only part of the variability in outcome (under-specification), the assumption of initial probabilistic equivalence – especially in small-sample studies – may be considerably weakened. In such cases, randomization may not create the covariance balance necessary to assume initial probabilistic equivalence, and biased results are possible. Although RCTs provide a strong defense against the violation of this assumption, in criminology, and in evaluation research generally, there is a long history of null findings that are, in part, attributable to a lack of statistical power (Lipsey 1990).
Clinical Equipoise. From a researcher’s perspective, uncertainty and clinical equipoise are moral imperatives for the conduct of ethical research (Weijer et al. 2000; cf. Veatch 2007). Equipoise is defined as genuine uncertainty as to which arm in an experiment is likely to prove more effective. Once a treatment is known to be effective, it is generally considered unethical to withhold that treatment. Mathematically, if there is true uncertainty of the effectiveness of the practice being tested relative to its alternative (some will be superior, some inferior, and some equal), adherence to equipoise limits progress in advancing evidence-based practice to discovering 25–50 % of successful treatments when they are tested in RCTs (Djulbegovic 2009). To the extent equipoise is achieved, the ethical implementation of RCTs may sorely constrain the advancement of knowledge.
What Evidence Gets Considered? The RCT focuses attention on the units that can be randomized and on interventions that are amenable to randomization. Thus, much of the RCT research focuses on recipient characteristics and who responds to the intervention being tested (e.g., publications that present multivariate evidence accounting for individual differences in displaying the outcome). Without minimizing the value of this information – which is useful for intervention targeting – such results provide little insight for improving service delivery or identifying the active ingredients of multicomponent interventions. Since service providers control these aspects of interventions, it seems that equal attention to these features is warranted. Multisite randomized trials can provide such evidence, but these are expensive and rare. Meta-analysis and systematic reviews of RCTs may also provide that evidence, but building the evidence base necessary is dependent on sufficient reporting of these details from the original trial. In sum, while the typical RCT may tell us for whom the intervention is effective, it may provide little information to advance our understanding of how and why interventions achieve their results.

A second implication of a commitment to RCTs as “gold standard” evidence may be an a priori filtering of the kinds of interventions that can have “gold standard” evidence of effectiveness. For example, environmental interventions are often not amenable to randomization. Thus, if only RCTs are accepted as credible evidence, our understanding of the impact of these interventions will be highly constrained. For example, Cozens, Saville, and Hiller in 2005 published a review of the effectiveness of crime prevention through environmental design (CPTED) strategies. Interestingly, only one title cited in the review’s bibliography contains the word “randomized.” Yet, while many studies of environmental interventions cited in this review do not meet the gold standard, the results that are included are encouraging. Equally important, as a practical matter, relative to individual-based interventions, the fidelity of environmental interventions does not degrade once they are implemented, nor do such interventions require booster sessions and additional resources to maintain impact. Had Cozens et al. dismissed evidence for CPTED practices not obtained through RCTs, their review would likely have been much shorter and a good deal of knowledge would have been lost to the field.
A third implication is that, by definition, RCTs are prospective studies. Randomized assignment must occur prior to the intervention, and this requirement obviates the use of retrospective data. Particularly in medicine – although they are increasingly available in other domains – electronic records provide a potential wealth of data for conducting comparative effectiveness studies. Commensurate with this growth are statistical matching methods that are increasingly robust in producing initial probabilistic equivalence permitting causal inference in retrospective and observational studies (Stuart 2010). Prospective data collection is expensive, and even small RCTs often require considerable costs to build effective sampling frames, to create buy-in with both controls and subjects, and to implement with fidelity. Providing incentives to a control or comparison group that receives limited, no, or delayed services may also be a nontrivial expense. The cost of collecting these data may, in part, explain the propensity of RCTs to focus almost exclusively on documenting intervention effectiveness, while often ignoring or omitting many other issues of concern to program adopters (such as cost, training, local acceptance of intervention theory and activities, and other issues of implementation or maintenance).
Finally, unintended consequences are often not discussed in RCT research. This is not to suggest that RCTs cannot collect and report this information, but merely an observation that RCTs typically focus on establishing the efficacy or effectiveness of a program through a circumscribed set of measures. These measures are defined by a logic model developed in advance of the trial and this focuses attention on the measures adopted prior to the start of a trial. If not associated with the measures defined in advance, unintended consequences may be ignored and are almost certainly unmeasured, and a biased understanding of the impact of the intervention may be promulgated. Morell (2005) offers some reasons for unintended consequences and guidance on how evaluation methodologies can be improved to account for these unforeseen and/or unforeseeable consequences.
Limitations to Knowledge Accretion. One of the major limitations of relying solely on RCTs for generating knowledge surrounds the accumulation of knowledge about effective practices. RCTs are best suited for establishing causal linkages between discrete phenomena (a manipulation and an outcome) that are linked by simple, short causal chains (Victora et al. 2004). In addition to the probabilistic constraints of equipoise, when RCTs are applied in real-world settings, they often assess the links between complex interventions and the individual mediators and moderators of distal outcomes. One method to account for that complexity is to use multivariate methods to report conditioned findings. That is, propensity adjustment may be used to account for selection bias, and multiple regression or other forms of statistical modeling are used to analyze the effects of the intervention. There are often good theory-building reasons for doing this, but because the partial or semipartial estimate of impact is determined by the variables in the model, findings from these studies cannot easily be used to examine the stability of evidence across multiple trials unless each researcher modeled the same variables. Suffice it to say, they do not, and the simple main effects that could be included in evidence synthesis are often not reported (Alford and Derzon 2012).
Also limiting knowledge accretion may be the number of researchers available to conduct RCTs and other experiments in criminology and criminal justice. Although the number of PhDs granted in the USA in criminology and criminal justice more than doubled between 1997–1998 and 2007–2008, still only 104 PhD degrees were granted in 2007–2008 (ASA, 2010). The June 2012 newsletter of the American Society of Criminology’s Division of Experimental Criminology boasts 167 active members (AEC/ DEC, 2012). While these numbers certainly do not represent the total number of researchers conducting or capable of conducting RCTs in criminology and criminal justice, it does seem fair to question whether the tremendous need to produce evidence, and to conduct original research and replications across all the varied settings and populations that exist, can be met by the supply of researchers available to conduct RCTs, or the funding available to support researchers conducting RCTs.
In the end, it is fair to ask how successful RCTs are in providing the evidence necessary to support evidence-based practice. Several federal and privately funded groups now conduct evidence reviews in which they evaluate the methods, procedures, and internal validity of RCTs to make best-practice recommendations. The Center for the Study and Prevention of Violence (CSPV, 2012) summarizes the results of 12 such efforts. Programs supported by RCTs that meet commonly accepted criteria for providing credible evidence are recommended as model, exemplary, effective, or perhaps promising programs. Although the list of effective programs compiled by CSPV is long (over 450 programs), when broken out by outcome or contrasted with the number of programs studied, the list takes on a different character. For example, of the 491 programs included on CSPV’s list in 2010, only 46 programs assessed a school-based ATOD or violence program, had implementation materials, and had been tested in two or more minimal quality trials (Alford and Derzon 2012). The Blueprints for Violence Prevention project at CSPV has examined over 900 programs to identify 11 effective and 22 promising violence prevention programs (CSPV, 2012). The problem is not limited to drug or crime studies. The US Department of Health and Human Services’ Office of Adolescent Health screened 1,000 studies to identify 28 programs that likely reduce the probability of teen pregnancy or birth (DHHS/OAH, 2011). As another example, the US Department of Education’s Institute of Education Sciences created the What Works Clearinghouse in 2002 and has screened at least 461 programs to improve academic achievement. Of these, 5 programs showed positive effects with a medium-to-large evidence base (DOE/IES, 2011).
The low ratio of programs of documented effectiveness relative to the number of programs examined suggests that relying on gold standard RCTs is not an efficient or a particularly effective standard on which to build evidence for science-based practice. It is possible that much of the evidence identified or submitted in support of these programs was not eligible because it was not obtained using an RCT, or that the RCTs submitted did not meet study quality inclusion criteria. Regardless, these numbers represent an astonishing paucity of evidence relative to need. As a corollary, how much skill, time, and money will be required to conduct high-quality RCTs that meet these study quality standards as valid, reliable, robust, and generalizable information for practice?
An Alternative: Seeing Beyond The Trees
The commitment to science-based intervention does not require a commitment to the RCT as the only path to identifying effective strategies for social betterment (Concato et al. 2000). It may be required for causal proof, but this is a standard that should follow and not lead the development of science-based practices. Alternative approaches are tenable and have proven useful. Key among these are natural experiments (e.g., difference-indifferences designs, regression discontinuity), adjustment for selection (e.g., matching, case-control, regression, fixed effects [sibling/person as own control], propensity scoring, and doubly robust estimation), and instrumental-variables analysis. Because of its applicability to criminology, the difference-in-differences approach is discussed in greater detail below.
Difference-in-differences (DID) approaches are natural experiments that contrast change in outcome for the intervention group (or groups) over time to change in one or more nonrandomly identified comparison groups. It is a popular design in criminology that relies, as perhaps all comparative research does, on the plausibility of the attribution that differences observed can be attributed to the intervention (Victora et al. 2004).
Given the many reasons outlined throughout this research paper and the pressing need to develop evidence of what works in real-world settings, it seems an appropriate moment in the development of science to consider how advances in scientific methods, accountability in social programming, and information technologies can be harnessed for science to improve the human condition. Increasingly, social programs are tracking and monitoring performance data for program improvement and accountability. The ubiquity of the personal computer, programs such as Microsoft Excel, and the development of the internet have made simple data management and the sharing of information over great distances possible. The past 20 years have seen a tremendous growth in the techniques and acceptance of meta-analytic methods for summarizing and analyzing findings generated by diverse instruments across uncoordinated settings. What is proposed is that these three phenomena be exploited to invert the phase model (e.g., Flay 1986; Greenwald and Cullen 1985) commonly adopted for advancing science to create a surveillance system that uses systematic data collection across multiple intervention settings to identify promising practices.
Using a synthetic DID model (S-DID) with distributed data collection and centralized analysis, local programs and evaluators would collect and submit summary performance data (i.e., pretest and posttest results) – and other relevant metadata (describing, e.g., the intervention, setting, and sample) – to a central repository that could then standardize those data and allow user-generated comparative effectiveness analysis. That is, findings from similar practices can be pooled to estimate average performance and the range of performance across multiple implementations, and these findings can be contrasted with performance scores from alternative practices. A user interface that graphically and quantitatively summarizes and displays the available evidence would give the local user tools to judge the breadth, depth, and consistency of evidence for each practice. Since findings are cumulative, the more settings that contribute, the more robust the estimates available. Homogeneous distributions of results are explained by sampling error, and metadata (user-provided information on setting, sample, and treatment characteristics) can be used by more sophisticated users to explore reasons for heterogeneity.
Persistent heterogeneity can be explored by adding categorical metadata variables to the system and entering results separately for each category. For example, if an intervention is hypothesized to be effective in urban but not rural settings, an urban/rural discriminator can be added to the metadata to distinguish subsequent submissions. As data in the two categories accrete, the homogeneity of evidence for each distribution can be tested and the results of the two distributions can be contrasted to confirm or refute the hypothesis. Hypothesized mediators that are continuous can likewise be entered as metadata and their influence on the outcome tested using correlational approaches.
Given the limitations of RCTs, the advantages of such a system are numerous. Interventions are tested in the settings in which they were adopted, and the diversity of adaptations, settings, and subjects provides an empirical basis for discerning what works where, when, and for whom. Because the diversity of interventions contributing to such a system is unlimited, opportunities for conducting ad hoc comparative effectiveness research – in near real time – are likewise unlimited. Since primary data are already being collected for performance monitoring purposes, the cost of maintaining such a service, once engineered, would likely be modest. But the greatest benefit by far is that, by allowing local implementers and local evaluators to contribute evidence, the system democratizes evidence generation: all users who contribute create the evidence necessary for identifying evidence-based best practices. Interventions in real-world settings are tested, and the opportunity for innovation is distributed to all intervention practitioners.
What Is Required?
At the local level, data on outcomes are collected from service recipients. Summary statistics are generated for both pretest and posttest (this keeps data collection relatively unobtrusive and maintains subject confidentiality). Descriptive data that describe the sample, setting, activities, and context of the intervention are provided by program administrators, agents, or local evaluators.
Using a web interface, these locally derived data are then entered into a centralized data repository that permits the user to see how their change score compared with other change scores from similar interventions and then map that distribution against alternative interventions (see Fig. 1). Evidence for generalizability and testing of potential confounds could be accomplished using similarity scores (e.g., clustering based on proximity scores, with a commensurate loss of data from filtering) or meta-regression.
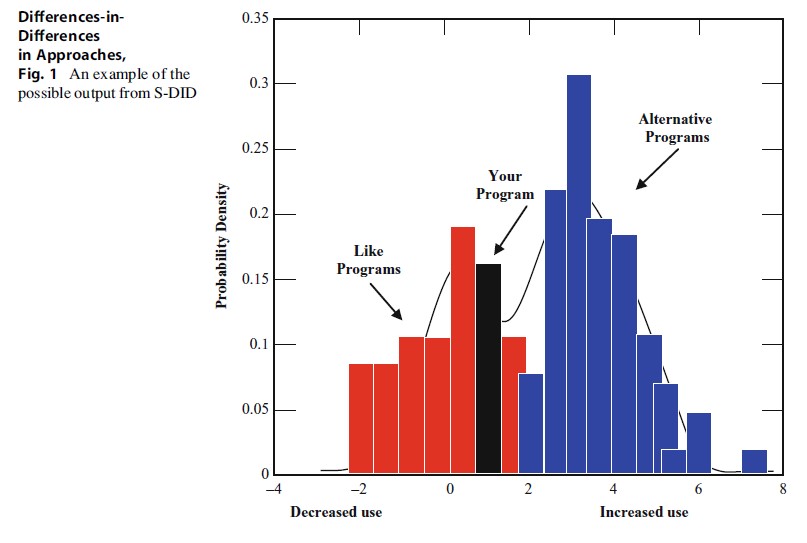 Differences-in-Differences in Approaches, Fig. 1 An example of the possible output from S-DID
Differences-in-Differences in Approaches, Fig. 1 An example of the possible output from S-DID
Limitations Of S-DID
For all its potential, the S-DID approach is not without its own set of limitations. Foremost is the fact that it is a system dependent on distributed data collection. If the infrastructure necessary to support such a system were built, would local implementers and evaluators upload the data necessary for the system to work? Such a system is worthless unless populated with data from a variety of settings and samples. Moreover, would the data entered be reliable and valid? Although the summary statistics necessary to populate an S-DID database are fairly basic (e.g., means and standard deviations), whether local implementers and evaluators accurately collect data and convert their primary data into the necessary summary statistics is a nontrivial consideration. If the data entered are biased, flawed, or otherwise corrupt, they will be of little value to advancing knowledge.
Because evidence from the proposed system comes from multiple sites, it ameliorates, but does not obviate, the possibility of misattribution. Only the RCT, well-implemented, controls for third-factor influences and permits causal attribution. In this system, intervention selection is not random, and there may be unmeasured factors correlated with intervention selection that drive the result. Nonetheless, as interventions are tested across multiple settings and samples, the evidence generated in this system is self-correcting; if third factors determine the result, their impact will become apparent over time and through follow-on implementations. In exchange for causal attribution, the S-DID system allows plausible attribution and an early warning system to identify both likely effective and likely ineffective practices.
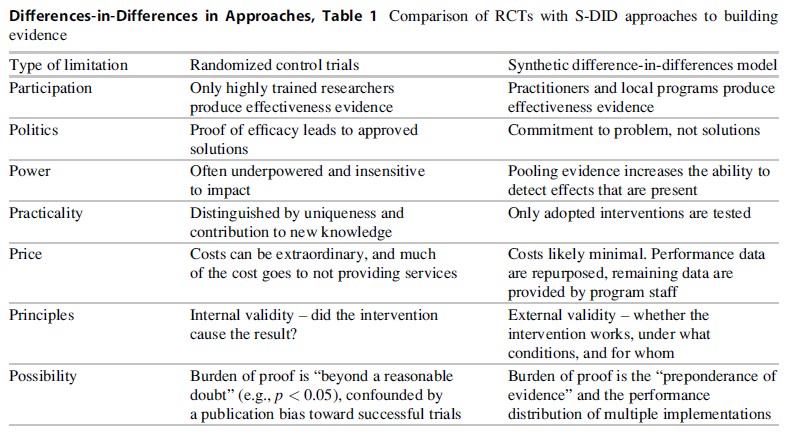 Differences-in-Differences in Approaches, Table 1 Comparison of RCTs with S-DID approaches to building evidence
Differences-in-Differences in Approaches, Table 1 Comparison of RCTs with S-DID approaches to building evidence
Can It Work?
Two efforts currently under way are using the proposed evidence system to identify best practices. The CDC, through its Laboratory Science, Policy and Practice Program Office, is using both published and partner-submitted quality improvement data to identify best practices for laboratory medicine (https://www.futurelabmedicine.org/about/; Christenson et al. 2011), and Bill Hansen and the author are developing a webbased system for managing local substance use prevention trial data (Evaluation-based Effectiveness Testing; DHHS Grant # DA026219). The National Evaluation of Safe Schools/Healthy Students used an S-DID approach to estimate the correlates of effectiveness in a sample of 59 grantees (Derzon et al. 2012). Across a variety of applications, the approach is providing evidence of practices associated with effectiveness.
In sum, S-DID circumvents many of the limitations of traditional RCT research (see Table 1). It is not offered as a panacea for all the limitations of RCT research, but may be expected to supplement RCTs in our quest to understand what interventions are likely to be effective, under which conditions interventions tend to be effective, and for whom those interventions may be effective.
Bibliography:
- Academy of Experimental Criminology, Division of Experimental Criminology (AEC/DEC) (2012) Newsletter. Academy of Experimental Criminology/The Division of Experimental Criminology Newsletter 7(1):1. Available at: http://gemini.gmu.edu/cebcp/ DEC/AECDECJune12.pdf. Accessed 9/20/2012
- Alford AA, Derzon J (2012) Meta-analysis and systematic review of the effectiveness of school-based programs to reduce multiple violent and antisocial behavioral outcomes. In: Jimerson S, Nickerson A, Mayer M, Furlong M (eds) Handbook of school violence and school safety, 2nd edn. Routledge, New York, pp 593–606
- American Sociological Association (ASA) (2010) Report of the ASA task force on sociology and criminology programs. American Sociological Association,
- Washington, DC. Available at: www.asanet.org. Accessed 8/7/2012
- Boruch RF (1975) On common contentions about randomized field experiments. In: Boruch RF, Riecken HW (eds) Experimental testing of public policy: the proceedings of the 1974 Social Science Research Council Conference on Social Experiments. Westview, Boulder, CO
- Center for the Study and Prevention of Violence (CSPV) (2012) Center for the study and prevention of violence: blueprints for violence prevention. Available at: http://www.colorado.edu/cspv/blueprints/ index.html. Accessed 9/7/2012
- Christenson RH, Snyder SR, Shaw CS, Derzon JH, Black RS, Mass D, Epner P, Favoretto AM, Liebow EB (2011) Developing laboratory medicine best practices: systematic evidence review and evaluation methods for quality improvement. Clin Chem 57:816–825
- Concato J, Shah N, Horwitz RI (2000) Randomized, controlled trials, observational studies, and the hierarchy of research designs. N Engl J Med 342: 1887–1892
- Cook TD, Campbell DT (1979) Quasi-experimentation: design and analysis issues for field settings. Houghton Mifflin, Boston
- Cozens PM, Saville G, Hillier D (2005) Crime prevention through environmental design (CPTED): a review and modern bibliography. Property Manag 23:328–356
- Department of Education, Institute of Education Sciences (DOE/IES) (2011) What works clearinghouse. Available at: http://ies.ed.gov/ncee/wwc/. Accessed 12/14/2011
- Department of Health and Human Services, Office of Adolescent Health (DHHS/OAH) (2011) Evidencebased [teen pregnancy prevention] programs. Available at: http://www.hhs.gov/ash/oah/oah-initiatives/ tpp/tpp-database.html. Accessed 12/14/2011
- Derzon JH, Yu P, Ellis B, Xiong S, Arroyo C, Mannix D, Wells ME, Hill G, Rollison J (2012) A national evaluation of safe schools/healthy students: outcomes and influences. Eval Prog Plann 35(2):293–302, 10.1016/j. evalprogplan.2011.11.005
- Derzon JH, Springer F, Sale L, Brounstein P (2005) Estimating intervention effectiveness: synthetic projection of field evaluation results. J Prim Prev 26: 321–343
- Djulbegovic B (2009) The paradox of equipoise: the principle that drives and limits therapeutic discoveries in clinical research. Cancer Control 16:342–347
- Durlak J, DuPre E (2008) Implementation matters: a review of research on the influence of implementation on program outcomes and the factors affecting implementation. Am J Commun Psychol 41(3):327–350, 10.1007/s10464-008-9165-0
- Flay BR (1986) Efficacy and effectiveness trials (and other phases of research) in the development of health promotion programs. Prev Med 15:451–474
- Glasgow RE, Lichtenstein E, Marcus AC (2003) Why don’t we see more translation of health promotion research to practice? Rethinking the efficacy-toeffectiveness transition. Am J Public Health 93(8): 1261–1267
- Greenwald P, Cullen JW (1985) The new emphasis in cancer control. J Natl Cancer Inst 74:543–551
- Gugiu PC, Gugiu MR (2010) A critical appraisal of standard guidelines for grading levels of evidence. Eval Health Prof 33(3):233–255. doi:10.1177/0163278710373980
- Hill AB (1952) The clinical trial. N Engl J Med 247(4):113–119. doi:10.1056/NEJM195207242470401
- Hunter JE, Schmidt FL (2000) Fixed vs. random effects meta-analysis models: implications for cumulative research knowledge. Int J Select Assess 8:275–292
- Lipsey MW (1990) Design sensitivity: statistical power for experimental research. Sage, Newbury Park
- Lipsey MW, Cordray DS (2000) Evaluation methods for social intervention. Annu Rev Psychol 51: 345–375
- Morell JA (2005) Why are there unintended consequences of program action, and what are the implications for doing evaluation? Am J Eval 26:444–463
- Overton RC (1998) A comparison of fixed-effects and mixed (random-effects) models for meta-analysis tests of moderator variable effects. Psychol Methods 3:354–379
- Pawson R (1994) What works in evaluation research? Brit J Criminol 34(3):291–306
- Reichardt CS (2011) Evaluating methods for estimating program effects. Am J Eval 32(2):246–272. doi:10.1177/1098214011398954
- Rothwell PM (2005) External validity of randomised controlled trials: “To whom do the results of this trial apply?”. Lancet 365:82–93
- Rubin DB (2005) Causal inference using potential out-comes. J Am Stat Assoc 100(469):322–331. doi:10.1198/016214504000001880
- Scientifically-based evaluation methods. Priority proposal by the US Department of Education. 68 Fed Reg 62445 (2003)
- Shadish WR, Cook TD, Campbell DT (2002) Experimental and quasi-experimental designs for generalized causal inference. Houghton Mifflin, New York
- Stuart EA (2010) Matching methods for causal inference: a review and a look forward. Statist Sci 25(1):1–21. doi:10.1214/09-STS313
- Victora CG, Habicht J-P, Bryce J (2004) Evidence-based public health: moving beyond randomized trials. Am J Public Health 94:400–405
- Weijer C, Shapiro SH, Cranley Glass K (2000) For and against: clinical equipoise and not the uncertainty principle is the moral underpinning of the randomised controlled trial. Br Med J 23:756–758
- Veatch RM (2007) The irrelevance of equipoise. J Med Philos Forum Bioethics Philos Med 32(2):167–183. doi:10.1080/03605310701255776
See also:
Free research papers are not written to satisfy your specific instructions. You can use our professional writing services to buy a custom research paper on any topic and get your high quality paper at affordable price.
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality

{kind=link}