
This sample History of Crime and Criminal Justice Statistics Research Paper is published for educational and informational purposes only. If you need help writing your assignment, please use our research paper writing service and buy a paper on any topic at affordable price. Also check our tips on how to write a research paper, see the lists of criminal justice research paper topics, and browse research paper examples.
This research paper provides an account of the history of statistics and its relation to criminal justice and criminology. It describes how the “Law of Errors,” initially based on astronomical observations, was adopted to explain “social physics” and in particular, the relative constancy of crime. Analytic methods that were developed to uncover patterns in data, which were not apparent prior to the utilization of the new methods, are described. Frequentist and Bayesian views of statistics are discussed, as well as issues surrounding some of the analytical methods used in criminology and criminal justice, including the concept of “statistical significance”; these issues are often glossed over by those who apply them.
Introduction
When a researcher in criminology and criminal justice does statistical analysis nowadays, all too often it goes like this. S/he:
- Gets permission to access a data set – for example, the National Longitudinal Survey of Youth (NLSY), the National Longitudinal Study of Adolescent Health (AdHealth), and the Project on Human Development in Chicago Neighborhoods (PHDCN)
- Then develops a “model” [about which Freedman (1985: 348) noted: In socialscience regression analysis, usually the idea is to fit a curve to the data, rather than figuring out the process that generated the data. As a matter of fact, investigators often talk about ’modeling the data.’ This is almost perverse: surely the object is to model the phenomenon, and the data are interesting only because they contain information about that phenomenon. Whatever it is that most social scientists are doing when they construct regression models, discovering natural laws does not seem to be uppermost in their minds]
- Calls it into one of the four Ss (SAS, SPSS, Stata, Systat) or some other collection of canned statistical routines
- Tweaks the model
- Looks for an encouraging p-value and starts writing.
This process was not always the case. First, data were hard to come by, and the researchers themselves often had to laboriously collect them. Second, and the topic of this research paper, there were very few methods available to perform the analyses. The early statisticians had to develop these methods – and perform the calculations without the aid of even a calculator.
This research paper describes the history of statistics and its relation to criminal justice, the analytic methods that were developed to uncover patterns in the data, and issues surrounding the analytical methods. The first section describes the early history of statistics used in demography. Section 2 describes the development of the “error law.” Section 3 then details how the “error law” was misapplied to criminal justice data. Sections 4 and 5 describe the development of new analytic methods in the early twentieth century as well as the development of statistical analysis in the field of criminology. Section 6 discusses how these methods lead to hypothesis testing and statistical significance.
Early History
The practice of searching extant records for patterns seems to have been initiated over three centuries ago by John Graunt (Hacking 1975: 102). Church records, not state records, were the original source of demographic information. While examining London’s church records of births and deaths (called Bills of Mortality), Graunt generated mortality tables that calculated the likelihood of an individual surviving to any age. These statistics were then used to estimate the number of London males eligible for military duty. As a result of this use of the Bills of Mortality, a number of European governments mandated that they be collected and provided to them (Hacking 1975: 102). One of Graunt’s contemporaries, William Petty, “was a man who wanted to put statistics to the service of the state” (Hacking 1975: 105); he termed this use of data “political arithmetic” (Porter 1986: 19). The word “statistics” (statistik in German) was coined by Gottfried Achenwall in 1749 (Hacking 1990: 24), and soon replaced Perry’s invention.
The first to use the Bills of Mortality for analytic purposes appears to be John Arbuthnot, who gathered data on birth cohorts at the end of the seventeenth century. He found that the ratio of male to female births was stable across years and location and wrote a monograph entitled “An argument for Divine Providence, taken from the regularity observed in the birth of both sexes” (Stigler 1986: 225). In other words, he equated this particular year-to-year regularity of an unequal number of births between males and females as proof of the existence of God. Since men lived lives that likely led to an early death, more men needed to be born each year compared to women.
[Of course, a statistician would point out that tossing a coin provides the same regularity, but perhaps s/he would not attribute this regularity to divine providence. Not only that, but ironically it took a Czech monk, Gregor Mendel, to show (in 1865) that even in genetics, a probabilistic model would suffice.]
Even earlier, in 1713, Jacob Bernoulli sought to explain such regularities in more detail. He determined that as the number of trials increased, the uncertainty about an event’s true proportion of successes would decrease. Bernoulli tested his propositions by considering an urn that contained a number of two different colored balls in regard to the chance of pulling a certain colored ball out of the urn. He later applied these ideas to real-life examples (Stigler 1986: 65). Instead of ascribing this regularity to divine providence, Bernoulli showed that as the number of births (or other binomial phenomena) increases, the true proportion will be approached, which is why there was stability in the proportion of births over 80 years of data (Stigler 1986: 64ff).
Twenty years later, Abraham De Moivre made a significant contribution to Bernoulli’s work on binomial statistics. He developed a formula that approximated the binomial probability distribution for a fair coin (p = 0.5), which resembles the symmetrical normal distribution of today. He showed that as the number of observations increases, the binomial distribution becomes a smooth curve which is highest at the true proportion (p) and whose logarithm drops off proportional to the square of the deviation from the mean. This led him to develop a concept similar to the central limit theorem, which was later refined by Pierre-Simon Laplace in 1781 (Stigler 1986: 136). These advances eventually led to the consideration of the concept and characteristics of statistical distributions since, although a particular value of p was the most likely outcome, values near p were also very likely.
A parallel effort in matters probabilistic was undertaken by Thomas Bayes in 1763. His eponymous theorem showed the way to update an estimate of a probability distribution or set of statistical parameters after one has obtained new data. His formula,
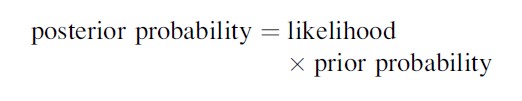
stands in contrast to the frequentist view of statistics, based on sampling theory, that provides a probability estimate of the data rather than of the parameters. As Lindley (1992: 360) noted,
The concept of a significance level or a confidence coefficient, although probability statements, are [sic] not about the hypotheses nor the parameters, but about the data. It is this failure to use probability for hypotheses and parameters that distinguishes the frequentist, sampling-theory approach to statistics from the fully-coherent Bayesian approach.
The prior probability refers to the initial belief of the probability of an event occurring, while the likelihood is the probability that other observations will occur given some new data, and finally the posterior probability is the new belief based on the prior and the likelihood. Over time, Bayes’ theorem has been advanced by many mathematicians and statisticians and had undergone serious critique but yet never disappeared (McGrayne 2011). In criminology it has been used in estimating recidivism parameters (Maltz 1984: 150) and in studying rational choice and deterrence (Anwar and Loughran 2011).
The “Law Of Errors”
[This section relies heavily on Stigler (1986).] Concepts related to statistical distributions were also found when considering measurement error. When repeated observations are made, for example, of the angle between the horizon and a star for navigational purposes, they rarely produce the same number. Dealing with the variation in these observations was an important statistical issue in the eighteenth century, especially for seaborne navigation out of sight of land. Building on De Moivre’s work, Thomas Simpson decided not to concentrate on the distribution of the observations but rather on the deviations between the observations and the true value or the errors (Stigler 1986: 90). While this may seem obvious now, at the time this was a major step forward since it moved away from the actual event, the observation itself, to an abstract quantity, the error, and its distributional properties.
Simpson made a number of simplifying assumptions about the error distribution and about the law of large numbers but was able to provide useful advice to astronomers that improved the way they dealt with error. But he (and Laplace after him) showed that the error curve was relatively symmetrical, and as the size of the error increases, the probability of it being that large should decrease monotonically away from zero.
Subsequent work by Carl Friedrich Gauss and Adrien-Marie Legendre showed that the mean of a series of observations minimized the sum of squares of the errors from the mean. Further, Gauss posited that the normal distribution (also known as the Gaussian distribution) was the appropriate distribution to use. His argument
was essentially both circular and non sequitur. In outline its three steps ran as follows: The arithmetic mean (a special, but major, case of the method of least squares) is only ‘most probable’ if the errors are normally distributed; the arithmetic mean is ‘generally acknowledged’ as an excellent way of combining observations so that errors may be taken as normally distributed (as if the ‘general’ scientific mind had already read Gauss!); finally, the supposition that errors are normally distributed leads back to least squares. (Stigler 1986: 141)
The Error Law, Crime, And “Social Physics”
In the nineteenth century, a Belgian physicist, Adolphe Quetelet, began to apply these new statistical tools to social data. France had begun to collect criminal justice statistics in 1825, and Quetelet noted the relative constancy in the number of persons accused of crime and the percent convicted (Stigler 1986: 179). Of course, there may have been other reasons for this constancy – police, prosecutorial, or judicial manpower limitations, arrest quotas, and a limited prison capacity – but these were not considered.
Instead, Quetelet saw in this statistical regularity “signs of a deeper social reality” and wrote of the “average moral man (l’homme moyen morale).” While considering how the repeated flipping of a coin with probability p would produce a distribution of outcomes centered on p, he posited that the same would hold for humans; there was a fixed value for social phenomena as well, deviations from this value being error. He surmised that “[I]f an individual at any given epoch of society possessed all the qualities of the average man, he would represent all that is great, good, or beautiful” (quoted in Stigler 1986: 171). And based on a mistake in the data, he noted a gradual decrease in the annual conviction rate and assumed that the population was getting more moral over time.
Simeon-Denis Poisson had a different view of the conviction process. Using corrected data, he modeled jury decision-making as a binomial process and found that the variation in rates over time was “not so large as to support a belief that there has been a notable change in the causes” (Stigler 1986: 190). In other words, the year-to-year variation was not, in current terminology, “statistically significant.”
Back to Quetelet essentially inverted the logic behind the “error law.” That is, he implicitly assumed that if errors are generally normally distributed, then whenever we find a distribution that is normally distributed we can safely assume that there is an underlying “truth.” This “truth” is a trait common to all persons but corrupted by errors. Quetelet called this truth a population’s penchant au crime: he wrote “Society prepares the crimes and the guilty person is only the instrument,” implying that “free will exists only in theory” (Hacking 1990: 116).
This idea that a population had fixed social characteristics, and that individual differences were due only to natural variation, continued to be believed. Emile Durkheim also concluded that there were social laws that acted on all individuals “with the same inexorable power as the law of gravity” (Hacking 1991: 82; see also Duncan 1984: 99). For example, he wrote of “suicidogenetic currents” in society, as if there was an innate propensity of the same magnitude for suicide within every individual (Hacking 1990: 158).

Others, especially Francis Galton (1889), criticized this approach. He saw variation as natural and desirable and criticized those who focused on averages as being “as dull to the charm of variety as that of the native of one of our flat English counties, whose retrospect of Switzerland was that, if its mountains could be thrown into its lakes, two nuisances would be got rid of at once” (quoted in Porter 1986: 129). Yet Galton’s view was not shared by most of the social scientists of the time. In fact, there was widespread belief that those far from the mean were deviant in the pejorative sense of the word and that they were “errors.” Statistics was not seen then so much as the science of variation (Duncan 1984: 224) as it was the science of averages.
Vestiges of this belief continue to this day (Savage 2009). In criminology, the General Theory of Crime (Gottfredson and Hirschi 1990) attributes all criminality to be generated by a single cause: lack of self-control. A lack of self-control may indeed lead a pedophile, a person engaged in insider trading, a serial killer, a drug dealer, and a pickpocket to perform criminal acts. However, making that assertion is no more useful than attributing all cancer to the same cause, uncontrolled cell growth: bone, breast, colon, lung, and prostate cancer have different etiologies, and each should be dealt with differently. They should not be looked upon as variations on a single theme.
Early Analytic Methods
Following in Galton’s footsteps, Karl Pearson made further improvements in statistical methods and helped to bring statistics into the social sciences. Pearson, in 1900, embraced the centrality of the normal curve in statistical theory by asserting that any measurement that was three standard deviations from the mean was significantly different from the mean. This new concept became known as the “rule of three.” Significance levels led way to early conceptions of hypothesis testing, which would eventually lead to the multitude of tests we have today (Ziliak and McClosky 2008).
In the 1920s Ronald Fisher introduced the concept of random sampling and controlled experiments. He accounted for individual variation and argued that control and experimental groups were needed to test treatments. The two groups needed to be generated by random assignment to one or the other from the study population, since each subject should have an equal and independent chance of being selected for either group. This would make it very likely (but not certain) that a representative sample populated both experimental and control groups.
Fisher also placed guidelines on determining a sample size. It is necessary to have a certain sample size based on characteristics of the groups in order to get reliable results. Nowadays power analysis software is used to determine the appropriate sample size for each group.
Fisher also promoted formal hypothesis testing and generated statistical tables for use by researchers to determine the level of “significance” of a finding. The “rule of 3” suggested by Pearson was not sufficient, and Fisher recommended setting an alpha level (often at 0.05) to determine “statistical significance.” The alpha level is the probability that the hypothesis (of “no difference” between, say, experimental and control groups) is correct. If this hypothesis is rejected, then it is concluded that there is a difference.
There is a controversy over significance testing that continues to this day (e.g., Cohen 1990, 1994; Loftus 1993; Maltz 1994a; Savage 2009; Wilkinson et al. 1999; Ziliak and McClosky 2008), due in part to the use of the term “significance.” Alfred Blumstein has suggested that the word “significance” be replaced with “discernibility,” since the nonstatistical meaning of the word “significance” is “importance”; many statistically significant findings are far from substantively significant, and what the tests actually show is the extent to which one measurement is discernible from another.
Experiments can be costly, and one cannot always generate a large enough sample to invoke the central limit theorem and the assumption of normality. William Gosset found this to be the case while working at the Guinness brewing company. Since his employers did not want their competitors to see how his statistical findings could benefit them, Gosset published his findings under the name “Student”, in 1908. He found that he could not use the standard z-score tables, which were based on the normal distribution. Instead, he developed a distribution useful for hypothesis testing with a small sample. Later on, Fisher would adjust the formula, and the Student’s t-distribution was created (Ziliak and McClosky 2008).
The accomplishments of these statisticians should not be underestimated. They had to deal with data that needed to be collected, often by themselves, with no computing aids except for statistical tables compiled with an enormous expenditure of time and patience. They were positing crude models that they hoped would give them insights into patterns of complicated processes. Their focus on means and variances was doubtless due to the fact that in order to develop findings of any value, they had to use summary statistics to characterize the distributions. That they succeeded so well in these endeavors is a testament to their perseverance and ingenuity.
The Twentieth Century And The Birth Of Criminology
In the 1920s, however, another way of looking at data was developed by University of Chicago sociologists (the “Chicago school” of sociology). Rather than base their analyses on a data set’s distributional properties (mean, standard deviation), they focused on its geographical variation. Two types of data emerged from this era: neighborhood data and ethnographic data.
Building on the work of Park and Burgess in The City (1925), Shaw and McKay (1942) collected data on the variation in juvenile delinquency rates in different neighborhoods in Chicago over several time periods and mapped the data. They then looked at the distribution of these rates and noticed that neighborhoods nearest the city center had the highest rates of delinquency, and as one moved away from the center, crime rates declined. In order to understand the reasons for the varying crime rates, they also gathered data on residential mobility, racial heterogeneity, and socioeconomic status. Shaw and McKay found that in areas with high crime rates, there was a large amount of residential turnover, racial heterogeneity, and low socioeconomic status, all of which decreased in places farther from the city center. Their findings supported the ecological perspective proposed by Park and Burgess. The methods of Shaw and McKay were highly influential and opened up the use of qualitative analysis in criminology (Noaks and Wincup 2004). It set the stage as well for geographical analyses in criminology, including computer-based crime mapping (Maltz et al. 1991) and hot spot analysis (Sherman and Weisburd 1995).
Another method of analysis used by the Chicago school was ethnographic analysis. In particular, the Chicago school is known for its use of life histories. In this method, a person is interviewed about his/her own personal history to understand the events in life that may have triggered crime and delinquency. One well-known life history study is The Jack Roller (1930) by Shaw, who interviewed a boy that had been institutionalized. Using official records, Shaw conducted the interview to fill in the story around each police interaction. Eventually an indepth story was put into a book that followed this boy’s delinquent career. This type of method allows the criminologist, or any researcher, to reach new causal hypotheses than can be further tested with data. Although ethnographies are qualitative and not statistical analyses, they can help derive new theoretical insight that can be studied with quantitative methods (Sampson and Laub 1993).
Hypothesis Testing And Statistical Significance
There has been a growing discontent with the (over)use of hypothesis testing and the search for statistically significant findings in the social sciences (e.g., Cohen 1990, 1994; Loftus 1993; Maltz 1994a). As a consequence, the American Psychological Association formed a committee, the Task Force on Statistical Inference (TFSI), to deal with it (Wilkinson et al. 1999), and various books (Lieberson 1985; Savage 2009; Ziliak and McClosky 2008) have taken up the cause as well.
In addition, there is growing evidence that many such findings may not be replicable, and often the initial finding turns out to be less “significant” due to regression to the mean. Moreover, journals are not interested in insignificant findings since they “show nothing.” Unfortunately, many interesting articles go unpublished that could have useful findings, since a null finding may have its own policy implications (Lehrer 2010).
These hypothesis tests are often based on a comparison of mean values. Using the mean assumes that there is a unimodal distribution based around the average of the sample; however, it is often the case that more than one type of behavior is present. [For example, there are many different homicide syndromes (Block and Block 1995: 29), each of which would have its own set of characteristics.] Nowadays there are a number of methods and techniques to deal with this, but these tests were first proposed when the costs of data collection and analysis, both in time and money, were substantially greater than today. Analyses that took days to accomplish can now be done in microseconds.
Moreover, the data analysis landscape has changed over the past few decades. We now have oceans of data to analyze, collected for us by criminal justice agencies and other organizations. Additional techniques, based on exploratory data analysis (Tukey 1977), have been brought to bear on data. A wealth of computer programs is at our disposal to facilitate the use of scores of analytic and visualization methods. As Tukey (1992: 444) noted, “If one technique of data analysis were to be exalted above all others .. ., there is little doubt which one would be chosen. The simple graph has brought more information to the data analyst’s mind than any other device.”
These innovations have brought data analysis into the mainstream of social science, while at the same time, they have made it so easy to deal with data that the assumptions that undergird the statistical methods are too often ignored. As described above, there is now a great deal of data available for analysis using tried-and-true (as well as tired and not-quite-true) methods.
Summary
As noted above, the data landscape has changed considerably over the past few decades. Courtesy of the US Department of Justice, we now have the FBI’s Uniform Crime Reports (UCR, from 1960) and the Bureau of Justice Statistics’ (BJS) National Crime Victimization Survey (NCVS, from 1973), each of which has provided researchers with useful information about the study of crime, criminal behavior, and official (and unofficial) responses to these acts. And courtesy of other federal agencies and other grantgiving organizations, we also have other survey-based data sets (NLSY, AdHealth, PHDCN) to test hypotheses and find relationships. Having these data sets publicly available provides researchers with the raw material on which to apply their statistical tools.
The statistical/methodological picture has also changed over the same time period, although not as quickly nor as much. Many still cling to methods developed long ago when reliable data were hard to come by. A host of new ways of analyzing data has been developed more recently.
It is important to understand the premises and assumptions that undergird whichever method one uses in research. Although very useful and innovative when they were first developed, hypothesis testing and its partner statistical significance may have outlived (most of) their usefulness. Their limitations, described in the cited papers and books by Cohen, Leiberson, Loftus, Maltz, Wilkinson, and Ziliak and McCloskey, are too often ignored by those who apply them. It is hoped that this review of their origins will lead to more their careful application and that greater (and appropriate) use is made of the methods described in other entries.
Bibliography:
- Anwar S, Loughran T (2011) Testing a Bayesian learning theory of deterrence among serious juvenile offenders. Criminology 49:667–698
- Block C, Block R (1995) Trends, risks, and interventions in lethal violence: proceedings of the third annual spring symposium of the Homicide Research Working Group. National Institute of Justice, US Department of Justice, Washington, DC
- Cohen J (1990) Things I have learned (so far). Am Psychol 45:1304–1312
- Cohen J (1994) The earth is round (p <.05). Am Psychol 49:997–1003
- Duncan OD (1984) Notes on social measurement: historical and critical. Russell Sage, New York
- Freedman DA (1985) Statistics and the scientific method. In: Mason WM, Fienberg SE (eds) Cohort analysis in the social sciences: beyond the identification problem. Springer, New York, pp 343–366
- Gottfredson M, Hirschi T (1990) A general theory of crime. Stanford University Press, Stanford
- Hacking I (1975) The emergence of probability. Cambridge University Press, Cambridge
- Hacking I (1990) The taming of chance. Cambridge University Press, Cambridge
- Hacking I (1991) How shall we do the history of statistics? In: Burchell G, Gordon C, Miller P (eds) The Foucault effect: studies in governmentality. University of Chicago Press, Chicago, pp 181–195
- Lehrer J (2010) The truth wears off. New Yorker. 13 Dec 2010; available online at http://www.newyorker.com/reporting/2010/12/13/101213fa_fact_lehrer
- Lieberson S (1985) Making it count: the improvement of social research and theory. University of California Press, Berkeley, California
- Lindley DV (1992) Introduction to Good (1952) rational decisions. In: Kotz S, Johnson NL (eds) Breakthroughs in statistics, volume I: foundations and basic theory. Springer, New York, pp 359–364
- Loftus GR (1993) A picture is worth a thousand p-values: on the irrelevance of hypothesis testing in the computer age. Behav Res Meth Instrum Comp 25:250–256
- Maltz M D (1984) Recidivism. Academic, Orlando. Internet version published in 2001; available at http://osu. academia.edu/MichaelMaltz
- Maltz MD (1994a) Deviating from the mean: the declining significance of significance. J Res Crime Delinq 31:434–463
- Maltz MD (1994b) Operations research in studying crime and justice: its history and accomplishments. In: Pollock SM, Barnett A, Rothkopf MH (eds) Operations research and the public sector (Chapter 7), Volume 6 of the handbooks in operations research and management science, edited by GL Nemhauser and AHG Rinnooy Kan. Elsevier, Amsterdam/Netherlands, pp. 201–262
- Maltz MD, Gordon AC, Friedman W (1991) Mapping crime in its community setting: event geography analysis. Springer, New York. Internet version published in 2000; available at http://osu.academia.edu/ MichaelMaltz
- McGrayne SB (2011) The theory that would not die: how Bayes’ rule cracked the Enigma code, hunted down Russian submarines & emerged triumphant from two centuries of controversy. Yale University Press, New Haven
- Noaks L, Wincup E (2004) Criminological research: understanding qualitative methods. Sage, London
- Park R, Burgess E (1925) The city. University of Chicago Press, Chicago
- Porter T (1986) The rise of statistical thinking. Princeton University Press, Princeton
- Sampson RJ, Laub JH (1993) Crime in the making: pathways and turning points through life. Harvard University Press, Cambridge
- Savage S (2009) The flaw of averages: why we underestimate risk in the face of uncertainty. Wiley, New York Shaw C (1930) The jack roller. University of Chicago Press, Chicago
- Shaw C, McKay H (1942) Juvenile delinquency and urban areas. University of Chicago Press, Chicago
- Sherman LW, Weisburd D (1995) General deterrent effects of police patrol in crime hot spots: a randomized, controlled trial. Justice Quart 25:625–648
- Stigler SM (1986) The history of statistics: the measurement of uncertainty before 1900. Harvard University Press, Cambridge
- Tukey JW (1992) The future of data analysis. In: Kotz S, Johnson NL (eds) Breakthroughs in statistics, volume II: methodology and distribution. Springer, New York, pp 408–452
- Tukey JW (1977) Exploratory data analysis. Addison-Wesley Publishing Company, Reading, Massachusetts Wilkinson L, Task Force on Statistical Inference (1999) Statistical methods in psychology journals: guidelines and explanations. Am Psychol 54:594–604
- Ziliak S, McClosky D (2008) The cult of statistical significance: how the standard error costs us jobs, justice, and lives. University of Michigan Press, Ann Arbor
See also:
Free research papers are not written to satisfy your specific instructions. You can use our professional writing services to buy a custom research paper on any topic and get your high quality paper at affordable price.
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality

{kind=link}