
This sample Single-Subject Designs Research Paper is published for educational and informational purposes only. If you need help writing your assignment, please use our research paper writing service and buy a paper on any topic at affordable price. Also check our tips on how to write a research paper, see the lists of psychology research paper topics, and browse research paper examples.
Since the emergence of psychology as an independent discipline in the late 1800s, research methods have played an ever-important role in the evolution of psychology. Early on, the adoption of research methods from the more established field of physiology helped distinguish psychology as its own separate discipline, distinct from philosophy and ultimately interested in gaining a reputation as a field that took its science seriously (Goodwin, 2005). In fact, if one were to travel back in time to the days of the earliest psychologists, one would notice that the field of psychology was a purely research-oriented discipline, a discipline whose primary goal was to elucidate the workings of the human mind.
Much has changed since those early days of psychology. Although many psychological researchers continue to examine topics that were of interest to early psychologists (e.g., memory, perception, consciousness), the field has expanded considerably. For example, whereas topics such as cognitive neuroscience and health psychology were well off the psychological map in the early to mid 1900s, they now demand the time and effort of many psychologists. Similarly, although clinical psychology was but a faint light on the distant horizon in the early 1900s, it now constitutes the single largest of subdiscipline in the field of psychology.
In fact, psychology has exploded to such an extent in the last 50 years that some psychologists would argue that now it consists of nothing more than a large number of disjointed subareas, many of which have little relation to one another (e.g., Kimble, 1999; Staats, 1999; Sternberg, 2005). Whether this point is true is arguably debatable—a debate I do not wish to enter at this time. Nevertheless, the rapid expansion of psychology has resulted in the rigorous study of a wide variety of topics that researchers approach from many different theoretical perspectives. Yet one common thread seems to bind these researchers together. Regardless of their vastly different educational backgrounds or widely divergent theoretical perspectives, psychologists tend to agree that research methods hold a venerated spot in psychology. As Stanovich (2001) suggested, research methods serve as the glue that holds together a discipline consisting of many different subdisciplines.
The most common approach to conducting psychological research—regardless of the specific topic one is studying or the specific theoretical orientation one takes when interpreting observational data—entails randomly assigning large numbers of subjects to different groups, manipulating an independent variable, controlling possible confounding variables, and comparing those groups to see if they differ on some dependent measure of interest. If the groups differ significantly at the end of the study, as shown by an appropriate statistical test, the researcher concludes that the independent variable likely caused the observed changes in the dependent variable. This approach, known as the large-N or groups approach (see Campbell & Stanley, 1963; Cook & Campbell, 1979), has been the dominant approach to conducting psychological research for nearly a century. A perusal of most psychology journals will show that researchers have preferred, and continue to prefer, this approach to learning about the phenomena they study (e.g., Baron & Perone, 1998; Blampied, 1999; Boring, 1954; Saville & Buskist, 2003). In addition, a large majority of research methods textbooks contain extensive discussions of how to conduct research using the groups-oriented approach (e.g., Kerlinger & Lee, 2000; Mitchell & Jolley, 2004). Thus, established researchers, whether implicitly or explicitly, continue to promote the idea that large-N group designs constitute the sine qua non for conducting psychological research. Moreover, students new to the field of psychology frequently come to believe that large-N designs are the only way to determine if there are meaningful relations among the variables they study.
Although large-N designs constitute the most popular means of studying psychological phenomena, another approach to conducting psychological research has a storied place in the history of psychology. Single-subject, or small-N} designs comprise yet another category of research designs that allows researchers to examine functional relations between variables. These designs, most commonly associated with behavior analysis, have become increasingly popular in psychology, most notably in areas of applied psychology where practitioners typically work with small numbers of people (Robinson & Foster, 1979; Saville & Buskist, 2003). The purpose of this research-paper is to discuss in more detail the use of single-subject designs in psychological research. Specifically, I will discuss (a) the history of single-subject designs in psychology, (b) problems with large-N designs and why single-subject designs have regained some popularity in the past 30 to 40 years, (c) characteristics shared by different single-subject designs, and (d) some of the most common single-subject designs.
History Of Single-Subject Designs
Although the use of large-N designs has been a veritable mainstay of psychological research since the early 20th century, research in psychology has not always followed this well-trodden path. In fact, some of the earliest psychological researchers conducted studies in which a small number of subjects responded under different treatment conditions, and the researchers measured the extent to which their subjects’ responses varied as a function of these manipulations. Gustav Fechner, for example, considered by many to be one of the founders of modern-day experimental psychology (Boring, 1957; Goodwin, 2005), conducted his early psychophysical research with just a handful of subjects. Similarly, Wilhelm Wundt, often called the “Father of Modern Psychology” because of his willingness to assert that psychology was its own discipline, typically asked individual subjects to introspect on their immediate conscious experience.
Around the same time Wundt and his students were attempting to examine the structure of mind, Hermann Ebbinghaus was conducting his seminal studies on memory. Unlike Fechner and Wundt, however, Ebbinghaus served as his own research subject. Consequently, the well-known retention curves that one can find in most introductory and cognitive psychology textbooks came from Ebbinghaus’ measurement of his own memory. Likewise, early learning theorists, including Edward L. Thorndike and Ivan P. Pavlov, used a small number of cats and dogs, respectively, to examine what many would come to know as instrumental (i.e., operant) conditioning and Pavlovian (i.e., classical) conditioning. In essence, then, the use of single-subject designs characterized the early days of experimental psychology.
Beginning in the early 1900s, however, the use of single-subject designs began to wane, and a new approach to conducting psychological research emerged. Influenced by the early statistical work of Sir Ronald A. Fisher (1925) and others, researchers soon found themselves developing studies that utilized large numbers of subjects and statistical analysis to identify significant between-groups differences in their dependent variables. By the mid-20th century, psychology was no longer a discipline that emphasized the use of small numbers of subjects under tightly controlled experimental settings. Instead, psychology was evolving into a discipline that focused on average group differences.
Although the use of many subjects and statistical analyses became a staple of psychological research in the mid-20th century—and has continued relatively unabated to this day—a handful of researchers persisted in their use of the single-subject designs that had been the hallmark of psychological research in the days of Wundt, Ebbinghaus, and Pavlov. The most ardent supporter of single-subject methodology was a relative newcomer to the field of psychology, a freshly minted assistant professor at the University of Minnesota who would soon become one of the most eminent psychologists in history. Burrhus Frederic (B. F.) Skinner, who in his 1938 treatise The Behavior of Organisms first outlined his “radical behavioristic” approach to the scientific study of behavior, suggested that the intensive study of a single organism would yield more information about the causes of behavior than a briefer comparison of large numbers of subjects. Skinner’s operant psychology eventually gave birth to a small but enthusiastic faction of experimental psychologists, among them Murray Sidman, whose influential Tactics of Scientific Research (1960) further outlined the single-subject approach to conducting research in psychology. Moreover, although large-N designs had supplanted the single-subject approach years earlier, applied behavior analysts continued to follow in Skinner’s early footsteps in their attempts to modify socially important behaviors (Baer, Wolf, & Risley, 1968). As Skinner (1966) later stated, “Operant methods make their own use of Grand Numbers: instead of studying a thousand rats for one hour each, or a hundred rats for ten hours each, the investigator is likely to study one rat for a thousand hours” (p. 21). Although Skinner enthusiastically exhorted the benefits of single-subject designs, his arguments did little to diminish the rise of large-N designs in psychology.
The Comeback Of Single-Subject Designs
Although large-N group designs surfaced in the 1920s and eventually became the dominant methodological approach to conducting research in psychology, the field, in fact, saw a modest reemergence of single-subject designs in the 1950s and 1960s. There were at least two primary reasons for the reemergence of single-subject designs during this time (see Robinson & Foster, 1979; Saville & Buskist, 2003).
First, with the rise of applied psychology in the mid-20th century came a need for research designs that would allow practitioners to accommodate smaller numbers of subjects but still see the efficacy of their interventions. Whereas many psychological researchers—especially those in academic or government settings who had easy access to a pool of research subjects—had the luxury of using large numbers of subjects in their studies, applied practitioners typically had neither the time nor the resources to conduct traditional large-N studies. Moreover, for reasons that seem fairly obvious, applied practitioners, especially those whose primary goal was to “hang out a shingle” and provide clinical services to needy clients, were probably reluctant to withhold treatment (due to the lack of a control group) from individuals who had sought out their services. Thus, single-subject designs provided applied psychologists with a way of determining the efficacy of their treatments without using large numbers of subjects or withholding treatment from vulnerable individuals.
Second, along with the ascension of Skinner’s operant psychology came an increase in the number of psychologists who bought into his philosophy regarding the use of single-subject designs. As the topics in which these researchers were interested grew more complex, there came a need for more sophisticated research designs that could accommodate the increasingly multifaceted questions these researchers were attempting to answer. As a result, many behavior analysts in the 1960s and 1970s spent a good amount of time developing new and improved single-subject designs. In addition, as single-subject designs became more sophisticated, growing numbers of researchers outside of behavior analysis began to identify ways in which they could use these designs to learn more about the varied phenomena they studied. As a result, one can now find researchers in many different quarters of psychology using various single-subject designs to examine their subject matter.
Problems With Large-N Designs
Thus, single-subject designs became more prevalent in psychology during the 1950s and 1960s because of the need for practical research designs that applied psychologists could use with small numbers of subjects and because researchers were developing more sophisticated single-subject designs. In addition, some researchers have also become increasingly reliant on single-subject designs because of flaws inherent in the more popular large-N group designs. Barlow and Hersen (1984) nicely outlined some of the problems with large-N designs (see also Johnston & Pennypacker, 1993; Sidman, 1960).
First, the large-N approach becomes potentially problematic when research questions revolve around the efficacy of a given clinical intervention. For example, imagine a large-N researcher who wished to examine the extent to which a new treatment positively impacted the severity of depression in young adults. Most often, large-N researchers would obtain a sample of clinically depressed subjects and then examine the efficacy of a certain treatment by randomly assigning subjects to the treatment condition or a control (i.e., no treatment) condition. In such cases, a question arises regarding the ethicality of withholding treatment from a group of subjects—in this case, a group of clinically depressed individuals—who may be in dire need of treatment. By withholding treatment in such a study, subjects in the control condition may, at best, not get any better, or may, at worst, continue to suffer. Although some clinical researchers attempt to rectify this issue by promising treatment to subjects in the control condition once the study is complete (Miller, 2003), this strategy does not negate the fact that some subjects in the control condition may suffer during the course of the study.
Second, the use of large-N designs may raise practical issues with regard to obtaining research subjects. Most often, the use of large-N designs requires, for statistical reasons, that researchers strive to include a minimum of 20 to 30 subjects in each group in their study. Thus, because most large-N designs include, at the very least, an experimental group and a control group, the number of subjects in such a study tends to be relatively large. Unfortunately, depending on the type of study, obtaining a sample of this size may be difficult. Assume, for instance, that a researcher is attempting to determine whether a new treatment reduces the severity of symptoms associated with schizophrenia. Because only a small percentage of individuals are schizophrenic, it may be difficult to obtain a large enough number of subjects so that the outcomes are statistically valid. Even if a researcher is able to obtain a large enough number of subjects to create a suitably valid study, other practical issues, such as paying subjects or finding time to collect data from a large sample of individuals, may create practical limitations that interfere with the researcher’s ability to conduct a scientifically sound study.
A third problem arising from the use of large-N designs concerns the averaging of group data. The most common practice in group research entails collecting data from a large number of subjects and then providing descriptive statistics for each group that typically include a measure of central tendency (e.g., mean) and a measure of variability (e.g., standard deviation). Based on how much the group distributions overlap, an inferential statistic (e.g., a t test or ANOVA) provides information regarding the likelihood that the groups are significantly different from one another.
Unfortunately, a measure of central tendency, although accurately representing the “average” response of the group, may not represent any single individual within that group (Sidman, 1960). For example, imagine a study on exercise and weight loss in which a researcher randomly assigned 100 subjects to either an exercise or a control condition. At the end of the study, the researcher finds that subjects in the exercise condition lost an average of 25 pounds and subjects in the control condition lost an average of 15 pounds, an outcome that might produce a statistically significant result. There is at least one potentially sizeable problem with these hypothetical results. Although subjects in the exercise condition lost more weight on average than subjects in the control condition, it is possible that no single subject lost either of these amounts of weight. Moreover, some subjects in the control condition may have actually lost more than 25 pounds, and some subjects in the exercise condition may have actually lost fewer than 15 pounds. Thus, although one might conclude that “exercise had a positive effect on weight loss,” closer analysis of the data shows that group averaging may have obscured some important observations about individual subjects—specifically, that other uncontrolled factors likely also influenced weight loss in at least some, if not many, of the subjects.
Averaging data also may conceal trends in a data set that might otherwise provide important information regarding the effects of an independent variable. Consider, once again, a study in which a researcher measured over eight weeks how diet or exercise affected weight loss in a sample of randomly selected and assigned college students. At the end of the study, the researcher finds that subjects in both conditions lost approximately 10 pounds, on average. Based on this observation, the researcher might conclude that diet and exercise are not significantly different with regard to how much weight loss they produce. Yet closer analysis of the data might reveal additional information that could be important to consider when making statements about the effects of diet or exercise on weight loss. For example, imagine that subjects in the diet condition lost the majority of their weight in the first two weeks of the study but lost little weight after that. In contrast, subjects in the exercise condition lost weight more slowly to begin with, but their weight loss was relatively consistent across all eight weeks of the study. For individuals who are hoping to lose weight and keep it off, this information might be especially important. Without examining individual data more closely, however, the researcher might overlook this important information.
Fourth, the way researchers typically conduct group research often creates problems when it comes to making statements regarding the generality of their findings. Most often, statements regarding the generality of a set of outcomes are based on the assumption that a sample of randomly selected subjects adequately represents some larger population. Thus, findings observed in a certain study are supposed to be an adequate indicator of what one would observe if the study were conducted with different individuals from the same population. Take, for example, a study on the factors that affect vocal tics in adults. One might assume that a randomly selected sample of subjects would represent all adults with vocal tics in every possible way (e.g., age, race, gender). In reality, however, researchers often do not have access to a truly random sample of subjects (e.g., Baron & Perone, 1998; Johnston & Pennypacker, 1993). Consequently, they end up recruiting subjects who are often unique in some way (e.g., introductory psychology students; see, e.g., Sears, 1986), which may severely limit the generality of their findings. In addition, even if researchers do have access to a truly random group of subjects, they often attempt to control individual differences as much as possible in an effort to increase internal validity and, consequently, the likelihood that they will observe a statistically significant outcome. For example, rather than using a truly random sample of subjects with a wide range of individual differences, researchers may limit their sample to subjects who are of a specific age, gender, race, background, and so on. Consequently, any significant findings may only hold for a very limited number of individuals with vocal tics and not for many in the greater population.
As Baron and Perone (1998) stated, “The emphasis on samples and populations is borrowed from the logic of inferential statistical analysis, the goal of which is to infer population parameters [italics added] (usually means and variances) from the scores of a representative sample of subjects” (p. 64). Unfortunately, many researchers who use large-N designs and inferential statistics make two important mistakes while interpreting the results of their studies. First, they make generalizations about their data that go beyond the populations from which they drew their relatively narrow samples; second, they make generalizations from a sample of subjects to individuals in a greater population. Ultimately, both of these practices greatly misrepresent the conclusions that one can make based on the outcomes of a single study.
Characteristics Of Single-Subject Designs
A perusal of any book devoted to single-subject methodology will reveal that there are, in fact, many different types of single-subject designs (e.g., Barlow & Hersen, 1984; Cooper, Heron, & Heward, 1987; Johnston & Pennypacker, 1993). Nevertheless, all of these designs, as strikingly different as they may seem, share certain characteristics. These characteristics include (a) the use of a small number of subjects; (b) exposure to all treatment conditions (i.e., all levels of the independent variable); (c) repeated measurement of the dependent variable under each treatment condition; (d) visual, rather than statistical, analysis of data; and (e) the use of direct and systematic replication in an attempt to make statements regarding the generality of findings (Saville & Buskist, 2003).
Number Of Subjects
Whereas traditional large-N group designs typically include a large number of subjects, single-subject designs utilize a much smaller number of subjects. Although the number of subjects in these studies may vary widely, most researchers who use single-subject designs employ no more than 10 to 12 subjects (and sometimes only 1 subject). For example, recent issues of the Journal of the Experimental Analysis of Behavior, the flagship journal for basic single-subject research, contain studies that most often used no more than 10 subjects, although a small number of studies used 20 or more subjects. In contrast, a recent issue of the Journal of Experimental Psychology: Learning, Memory, and Cognition, a leading outlet for basic experimental research conducted in the large-N tradition, contains studies that used no fewer than 16 subjects and sometimes as many as several hundred subjects. Whereas the use of large numbers of subjects in traditional group research rests on certain statistical assumptions, single-subject researchers believe that functional relations can be gleaned using only 1 subject responding under different treatment conditions.
Exposure To All Treatment Conditions
In traditional large-N group designs, subjects typically receive exposure to only one level of the independent variable. For example, in one of her early studies on the malleability of memory, Elizabeth Loftus (1975) assigned subjects to different treatment conditions in which they did or did not receive “leading” questions about a video they had observed (e.g., “Did you see the school bus in the film?” or “Did you see a school bus?”). Loftus then examined the extent to which subjects in each group later remembered seeing a bus in the video. She observed that subjects given the leading questions were more likely to report seeing a bus than subjects who did not receive the leading questions.
In the large majority of studies conducted in psychology (e.g., Baron & Perone, 1998; Blampied, 1999; Saville & Buskist, 2003), a researcher randomly assigns subjects to groups, or treatment conditions, and then examines the extent to which the “average” subject in the conditions differs after exposure to the different treatments. Because random assignment means that the outcome of a coin toss, for example, determines whether subjects will be in one group or the other (e.g., “heads,” you’re in Group 1; “tails,” you’re in Group 2), each subject ends up experiencing only one of the treatment conditions.
In contrast, subjects in studies that utilize single-subject designs typically experience all levels of the independent variable, or all treatment conditions. Take, for example, an early study by Hall, Lund, and Jackson (1968) in which they examined the effects of social reinforcement on studying behavior in elementary school students. Hall et al. first measured “on-task” studying behavior in six subjects under a baseline, or control, condition (i.e., in the absence of social reinforcement for appropriate studying). In the subsequent treatment condition, Hall et al. taught the teachers to deliver social reinforcement (e.g., a pat on the shoulder) to the students when they were on task and measured the accompanying changes in studying. Hall et al. then reintroduced the baseline condition and examined if on-task studying returned to its initial baseline levels. Finally, Hall et al. introduced the social reinforcement condition one last time, examined its effects, and observed that the contingent presentation of social reinforcement increased studying behavior relative to baseline levels.
Whereas a more traditional large-N groups approach to examining the effects of social reinforcement on studying might have entailed the random assignment of a large number of students to either a “social reinforcement” condition or a control condition, the subjects in Hall et al.’s study experienced each treatment condition twice: baseline, social reinforcement, baseline, and social reinforcement. In this way, each subject served as his or her own “control,” against which Hall and his colleagues compared the effects of social reinforcement. Thus, regardless of whether each subject was on task a lot or very little during baseline, Hall et al. were able to examine the extent to which social reinforcement affected the unique studying behavior of each individual child.
Measurement Of The Dependent Variable
In most large-N designs, researchers typically measure the dependent variable of interest no more than once under each treatment condition. To illustrate, consider a series of studies on stereotype threat by Steele and Aronson (1995). In their studies, Steele and Aronson asked white and black college students to take a 30-item test consisting of questions taken from a Graduate Record Examination study guide. Students did so under one of three treatment conditions: (a) a “diagnostic” condition, in which Steele and Aronson presented the questions as a valid test of intellectual ability; or (b) one of two slightly different “nondiagnostic” conditions, in which participants believed they were simply solving verbal problems and that the test did not involve a real test of intellectual ability.
Steele and Aronson (1995) found that black students in the diagnostic condition performed more poorly than black students in either of the nondiagnostic conditions. They also observed that black students in the diagnostic condition performed more poorly on the quiz than white students in the same condition but not differently from white students when they believed the test was not a true test of intellectual ability. Notice that Steele and Aronson measured their dependent variable only once for each subject. Once they had obtained a test score from each student, they calculated an average score for subjects in each treatment condition and then compared the outcomes statistically.
In contrast, single-subject designs entail the repeated measurement of the dependent variable under each treatment condition. More specifically, single-subject researchers usually measure their dependent variables under each baseline and treatment condition until the behavior of interest has stabilized. Although there are no formal rules for determining whether a particular response is stable, most single-subject researchers agree that at least three data points are needed to determine if a response is stable or if a particular behavioral trend exists (Johnston & Pennypacker, 1963; Sidman, 1960).
For example, consider a study by Smith and Ward (2006) in which they examined the effects of public posting (i.e., posting public information on a player’s performance) and goal setting on several different skills in three college football players. Smith and Ward first examined the percentage of times that each player performed the skills (e.g., blocking, running a correct route) correctly under a baseline condition that consisted of 16 practice sessions and two games. Then, Smith and Ward introduced public posting and examined how it affected the players’ performances over the course of four more practice sessions and one game. Following another four-session (three practices and one game) baseline condition, Smith and Ward measured their subjects’ performances under a “goal setting” condition (six practices and two games), another baseline condition (three practices and one game), and a “public posting and goal setting” condition (six practices and two games). In total, Smith and Ward measured each skill a total of 47 times under the different conditions and found that public posting and goal setting increased the extent to which their subjects performed the different skills correctly.
There are at least three reasons why single-subject researchers prefer to measure their dependent variables multiple times under each condition (Saville & Buskist, 2003). First, repeated measurement may allow a researcher to identify and subsequently control further extraneous factors that may be introducing unwanted variability into the study. If, for example, a subject’s responding is quite variable during a particular phase of a study, a researcher may try to identify and remove any additional factors that may be contributing to the observed variability. By doing so, a researcher can increase the likelihood that any changes in behavior are, in fact, a function of independent variable manipulations and not some other uncontrolled factor. In contrast, researchers who use large-N group designs often “weed out” such unwanted variability by using (a) random assignment, which, they assume, will equally distribute unwanted factors to each treatment condition; and (b) statistical analysis, which will tell them how much of the variability in their study is due to random, extraneous factors and how much is due to the independent variable.

Second, single-subject researchers prefer repeated measurements because it affords them the opportunity to interact very closely with their data and manipulate an independent variable at a moment’s notice if they wish to do so. For example, imagine a team of researchers studying the effects of a new treatment of self-injurious behavior (SIB) in mentally retarded adults. If our research team introduced a treatment and subsequently realized that the treatment was, in fact, exacerbating the frequency of SIB, they could modify the treatment on a whim in hopes of reducing the potentially damaging behavior. Thus, repeated measurement of the dependent variable allows single-subject researchers to examine the effects of one or more independent variables while they are in the process of collecting their data. In contrast, large-N researchers typically measure their dependent variables only once. Consequently, they can examine whether their groups are significantly different (i.e., whether their independent variables had an effect) only after they have completed their data collection. Perone (1999) suggested that the traditional practice of measuring a dependent variable only once keeps researchers from having the intensive interaction with their data that they need to obtain a true understanding of the relation between their independent and dependent variables.
Finally, the introduction of a new treatment condition may produce reactivity on the part of the subjects. Consequently, a subject’s first response may not be the response that a researcher would observe once the novelty of the new treatment wore off. For example, consider a study in which a researcher wanted to know whether the contingent presentation of movie gift certificates increased the number of minutes that college students exercised each day. The introduction of such a novel treatment might initially result in an increase in the amount of time that subjects exercise during the first week or two. However, with repeated measurement, our researcher might find that the gift certificates do not have a long-lasting effect and that exercise might ultimately fall to a level that is considerably lower than what she observed during the first two weeks. Only with repeated measurement would our researcher be able to determine the long-term effects of her intervention. If, however, our researcher had measured the dependent variable only once or twice, he or she may have come to the mistaken conclusion that the contingent presentation of movie gift certificates may be an effective way to increase exercise in college students.
Analysis Of Data
Psychological researchers have a long and storied tradition of using statistical procedures to analyze the outcomes of their studies. Although early research in the history of psychology did not employ common statistical analyses (simply because such analyses had yet to be developed), the introduction of statistical tools such as the Pearson correlation coefficient, the t test, and analysis of variance (ANOVA) gave psychological researchers new and exciting ways to analyze their data. Specifically, inferential statistics provided researchers with a quantitative means of determining whether their groups were meaningfully different.
Thus, after researchers have collected their data using traditional large-N methods, the use of hypothesis testing and inferential statistics allows them to determine whether any difference in group means was due to random, uncontrolled factors or whether the difference was due to the effects of the independent variable. In addition, the relatively recent introduction of new statistical concepts (e.g., power, effect size) has allowed researchers to be even more certain of the statements they make regarding relations between their variables.
In contrast, single-subject researchers typically analyze their data using visual analysis. More specifically, they often plot their data on line graphs and analyze whether there seem to be meaningful differences in responding under different treatment conditions. For example, imagine once again that a researcher was examining whether a new treatment reduced SIB in a developmentally disabled child. After measuring the child’s behavior in the absence of the treatment (i.e., baseline), the researcher might introduce the treatment and measure the instances of SIB every day for the next week. After the number of SIB episodes had stabilized, the researcher might then remove the treatment (i.e., an A-B-A design; see below) and examine whether there seem to be noticeable differences in steady-state levels of responding under the baseline and treatment conditions (see Figure 10.1a). If there is little overlap in the data points under each condition, our researcher can conclude with some confidence (assuming other extraneous factors have been controlled) that the treatment was likely responsible for the observed differences. Depending on the study and what type of behavior is being measured, researchers might also look for different trends in responding (see Figure 10.1b). Finally, although there are no explicitly stated rules for determining whether a response has stabilized or whether there are significant differences across treatment conditions (Sidman, 1960), most single-subject researchers tend to agree that a visually significant difference likely denotes a statistically significant difference and that visual analysis provides a valid method for analyzing functional relations between variables.
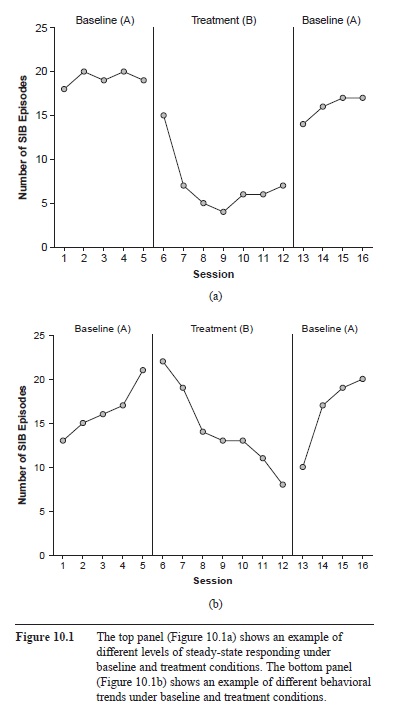 Figure 10.1 The top panel (Figure 10.1a) shows an example of different levels of steady-state responding under baseline and treatment conditions. The bottom panel (Figure 10.1b) shows an example of different behavioral trends under baseline and treatment conditions.
Figure 10.1 The top panel (Figure 10.1a) shows an example of different levels of steady-state responding under baseline and treatment conditions. The bottom panel (Figure 10.1b) shows an example of different behavioral trends under baseline and treatment conditions.
Even though visual analysis has been the method of choice for analyzing data in single-subject designs, it is becoming increasingly common for single-subject researchers to use statistical tools. Consider, for example, recent research on delay discounting, which examines the extent to which subjects discount, or devalue, rewards as a function of the delay in their receipt. Most often subjects in these studies complete a series of choice trials in which they decide between a smaller, immediate reward and a larger, delayed reward (e.g., “Would you prefer $100 delivered immediately or $200 delivered in one week?”). By examining subjects’ choices across many different delays and reward magnitudes, researchers have determined that subjects frequently discount rewards in a pattern that can be nicely described by a hyperbola-like mathematical function (Green & Myerson, 2004; Rachlin, Raineri, & Cross, 1991). In addition, numerous studies on delay discounting have examined the extent to which different groups discount delayed rewards differently. Bickel, Odum, and Madden (1999), for instance, found that smokers discounted delayed rewards faster than nonsmokers, and Green, Fry, and Myerson (1994) observed that children discounted delayed rewards faster than young adults, who, in turn, showed greater discounting than older adults.
Although most researchers who study delay discounting present visual data that provide information on individual and group differences in discounting (for an example see Figure 10.2), many also include statistical analyses that give a quantitative description of the differences among individuals and groups (e.g., Myerson, Green, & Warusawitharana, 2001). Although some single-subject proponents have suggested that the use of statistical analysis is not necessary and may actually be detrimental when attempting to identify “real” relations among variables (e.g., Baer, 1977; Michael, 1974; Perone, 1999), others have suggested that statistical analysis can be a useful addition to the experimental toolkit of single-subject researchers (e.g., Crosbie, 1999; Davison, 1999).
Methods Of Generalization
Since the introduction of inferential statistics by Fisher and others in the early 1900s, researchers have focused their efforts on obtaining samples of subjects that supposedly represent the greater populations from which the subjects came. Most often this strategy entails choosing a large number of subjects, collecting data, and then inferring the extent to which any observed findings are likely to be reproduced in the greater population. Thus, when using college students, for instance, researchers often try to obtain a large sample of subjects that represents in as many ways as possible the complete population of college students they are attempting to study. By doing so, large-N researchers suggest that any findings they obtain will not only describe the sample of subjects in their study, but might also describe the larger population of subjects who did not participate in the study. Moreover, by using a relatively diverse sample of subjects, large-N researchers suggest that observed outcomes might even generalize to other settings or times.
In contrast, single-subject researchers rely on replication, which ultimately serves two important functions (Johnston & Pennypacker, 1993). First, replication helps researchers determine whether their observations are replicable under similar conditions. Replicating a set of observations under similar conditions increases one’s certainty regarding the “real” relations among variables. Second, single-subject researchers also want to know whether their observations will hold under different conditions, which provides information regarding the generality of a set of findings. In an attempt to answer these questions, single-subject researchers focus on two types of replication: direct replication and systematic replication.
Direct replication entails repeating the original procedures of a study as closely as possible, in hopes of deter-mining whether an observation is reliable. As Johnston and Pennypacker (1993) noted, this type of replication may take many forms. For example, a researcher might be interested in whether a single subject continues to respond in the same way, under the same treatment condition, during a single experimental session (within-session replication). In contrast, a researcher might want to know whether two or more subjects in the same experiment respond similarly under the same treatment conditions (within-experiment replication). Or a researcher who earlier conducted a study with college women, for example, may want to know whether another researcher observed the same pattern of responding when replicating a study with a different sample of college women (within-literature replication). In each case, a researcher replicates some aspect of a study as closely as possible and notes the resulting outcomes. Finally, although direct replications focus mostly on the reliability of a set of findings, they may provide tentative information regarding generality if a series of studies occur at different times or use slightly different subjects.
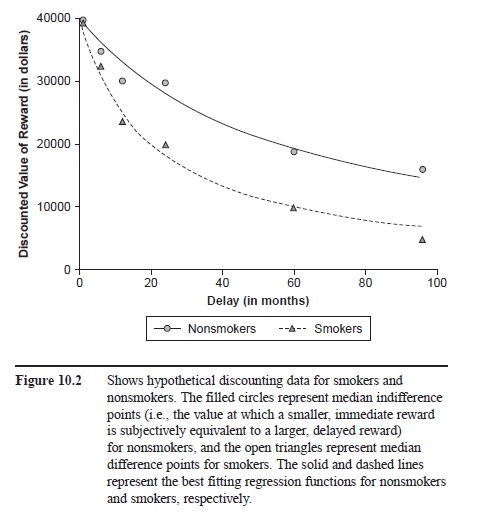 Figure 10.2 Shows hypothetical discounting data for smokers and nonsmokers. The filled circles represent median indifference points (i.e., the value at which a smaller, immediate reward is subjectively equivalent to a larger, delayed reward) for nonsmokers, and the open triangles represent median difference points for smokers. The solid and dashed lines represent the best fitting regression functions for nonsmokers and smokers, respectively.
Figure 10.2 Shows hypothetical discounting data for smokers and nonsmokers. The filled circles represent median indifference points (i.e., the value at which a smaller, immediate reward is subjectively equivalent to a larger, delayed reward) for nonsmokers, and the open triangles represent median difference points for smokers. The solid and dashed lines represent the best fitting regression functions for nonsmokers and smokers, respectively.
Systematic replication, in contrast, occurs when researchers repeat a study but introduce conditions that are different from the original study. Remember that the primary purpose of systematic replication is to determine the generality of a specific outcome. To illustrate, consider a series of recent studies on a new instructional method known as interteaching (Boyce & Hineline, 2002). In one study, Saville, Zinn, and Elliott (2005) examined in a controlled laboratory setting whether college students in an interteaching condition received better scores on a short quiz than students in a reading, lecture, or control condition. Saville et al. observed that students in the interteaching condition answered correctly a significantly greater percentage of questions than students in the other three conditions.
To examine the generality of these results, Saville, Zinn, Neef, Van Norman, and Ferreri (2006) conducted a systematic replication in which they compared inter-teaching to lecture in a regular college class. In support of Saville et al.’s (2005) findings, Saville et al. (2006) also observed that students typically performed better on exams following exposure to interteaching than when they had encountered the same information via a traditional lecture. Thus, the efficacy of interteaching as a potentially effective alternative to traditional lectures seems to generalize beyond controlled laboratory settings into less controlled classroom environments.
Ultimately, by conducting both direct and systematic replications, single-subject researchers can state with confidence the extent to which the variables they study are related and whether their observations are likely to hold under different conditions. In this way, single-subject researchers systematically build a knowledge base that g, 40 allows them to learn more about basic behavioral processes and apply this knowledge in hopes of modifying socially meaningful behavior.
Types Of Single-Subject Designs
In general, there are two categories of single-subject designs: (a) reversal designs, in which a researcher introduces and subsequently removes one or more treatments; and (b) multiple-baseline designs, in which a researcher staggers the introduction of a treatment across behaviors, subjects, or settings. Each of these designs allows researchers to obtain information on the functional relations among variables.
Reversal Designs
A-B Design
The most basic single-subject design is the A-B design, in which researchers first measure the dependent variable under a baseline (A) condition to see how a subject behaves “normally,” and subsequently under a treatment (B) condition to see if the subject’s behavior changes. To illustrate, consider once again a hypothetical study in which researchers examined the effects of goal setting on the execution of various football skills (e.g., blocking; see Smith & Ward, 2006). Using an A-B design, the researchers would first measure how each football player blocked correctly in the absence of goal setting. Then, after a player’s performance had stabilized, the researchers would ask the player to set goals for himself and measure any concomitant changes in blocking (see Figure 10.3). If the introduction of goal setting was accompanied by meaningful changes in blocking, the researchers might conclude that their independent variable was responsible for the changes. Unfortunately, because the treatment in A-B designs is not subsequently withdrawn (reversed back to baseline), researchers cannot determine with any certainty that changes in the dependent variable during the B phase were due to the treatment or to other extraneous factors that occurred at the same time. For this reason, researchers rarely use A-B designs if their goal is to identify functional relations.
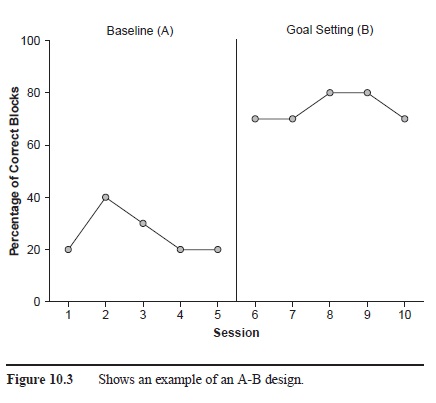 Figure 10.3 Shows an example of an A-B design.
Figure 10.3 Shows an example of an A-B design.
A-B-A Design
The A-B-A, or withdrawal, design is the logical extension of the A-B design. With A-B-A designs, researchers measure the dependent variable under baseline, introduce the treatment, and then reintroduce the baseline condition again (i.e., withdraw the treatment). Thus, in the case of the previous example, researchers would measure blocking under baseline, introduce goal setting, and then subsequently remove the treatment and see how blocking performance changed (see Figure 10.4). Whereas the A-B design would not necessarily allow the researchers to draw conclusions regarding functional relationships between their variables, the A-B-A design is the simplest single-subject design that allows a researcher to make such functional statements. Specifically, if the dependent variable (e.g., proper blocking) changes only when the treatment (e.g., goal setting) is introduced and subsequently removed, researchers can be relatively certain that their manipulations were responsible for the observed changes.
A-B-A-B Design
An extension of the A-B-A design is the A-B-A-B design, in which a treatment is introduced after an initial baseline condition, subsequently removed, and then introduced again (see Figure 10.5). Thus, whereas the A-B-A design ends with baseline (i.e., the absence of a treatment), the A-B-A-B design ends with behavior occurring under a treatment condition. The addition of a second treatment condition may be important for at least two reasons. First, if the dependent variable changes once again with the reintroduction of the second B phase, a researcher can be even more certain that the treatment was responsible for the observed changes. Second, the reintroduction of a treatment condition may be important for ethical reasons. Consider, for instance, a subject who is engaging in severe SIB. If a treatment is effective at reducing the incidence of SIB, ending a study in a baseline phase might put the subject at risk if the SIB returns. Of course, depending on the purpose of the study, researchers might extend the A-B-A-B design to include more treatment presentations and withdrawals (e.g., A-B-A-B-A-B design).
Multiple-Treatment Designs
In contrast to the preceding designs in which researchers introduce only one treatment condition, multiple-treatment designs are those in which researchers introduce more than one treatment condition. Examples of multiple-treatment designs would include A-B-A-C and A-B-A-C-A-D designs, in which a researcher alternates several treatments with baseline; A-B-C-D-B-C-D designs, in which a researcher alternates several treatments without reestablishing baseline before and after each; and A-B-A-C-A-BC-A designs, in which a researcher examines the effects of more than one treatment, individually and then together (see Figure 10.6 for an example of an A-B-A-C design). Again, depending on the purpose of the study, researchers may choose to use variations of these designs.
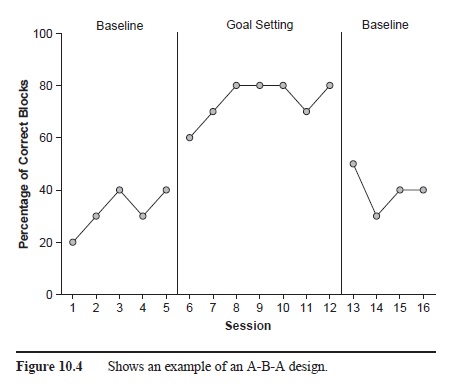 Figure 10.4 Shows an example of an A-B-A design.
Figure 10.4 Shows an example of an A-B-A design.
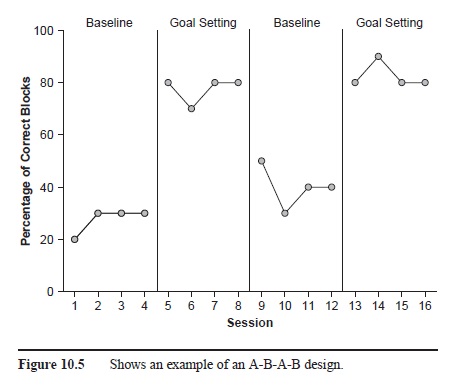 Figure 10.5 Shows an example of an A-B-A-B design.
Figure 10.5 Shows an example of an A-B-A-B design.
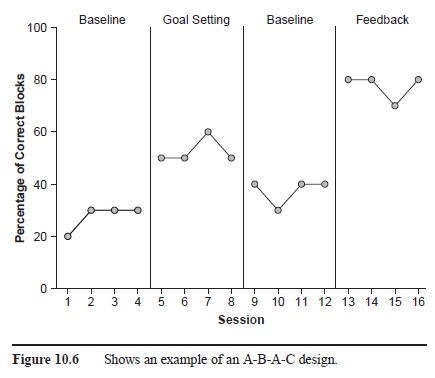 Figure 10.6 Shows an example of an A-B-A-C design.
Figure 10.6 Shows an example of an A-B-A-C design.
When considering which multiple-treatment design to use, single-subject researchers often have to consider the pros and cons of using each. For example, with A-B-A-C and A-B-A-C-A-D designs, researchers may be able to determine with more certainty the extent to which each treatment affected their dependent variables. By reestablishing baseline before and after each treatment condition, researchers are more likely to see the “real” effects of each treatment and not the effects of carryover from a preceding condition. However, reestablishing baseline after each treatment condition may be time-consuming, which could be an issue depending on the resources researchers have at their disposal (e.g., Cooper et al., 1987). Similarly, with an A-B-C-D design, for example, researchers may be able to study multiple treatments in less time, but carryover or order effects may make it difficult to determine how each treatment in isolation affects the dependent variable. Fortunately, counterbalancing the order of conditions with all reversal designs (e.g., using an A-B-A-C design with some subjects and an A-C-A-B with others) may help researchers determine how different treatments are affecting the behavior of interest. Ultimately, the type of multiple-treatment design that researchers choose to use in their studies may depend on the specific purpose of their study.
There are three general variations of the multiple-baseline design (see Cooper et al., 1987). The preceding example constitutes a multiple baseline across subjects design, in which the same behavior is investigated in different subjects in the same setting. A multiple baseline across settings design examines the same behavior in the same subject, but in different settings. Finally, a multiple baseline across behaviors design examines different behaviors in the same subject and setting. Each of these designs provides useful information regarding functional relations as well as information regarding the generality of a particular treatment. Finally, although multiple-baseline designs do not allow researchers to examine the effects of an independent variable directly (i.e., by introducing and removing a treatment) and, thus, are considered by some to be weaker than reversal designs for examining functional relations (Cooper et al., 1987), these designs still provide a useful and practical way for researchers and practitioners to examine the extent to which their treatments produce changes in a behavior of interest.
Multiple-Baseline Designs
Multiple-baseline designs offer an alternative to reversal designs when researchers (a) are studying behavior that is irreversible or (b) do not wish to remove a treatment but still wish to identify functional relations between their variables (Baer et al., 1968; Cooper et al., 1987). In essence, multiple-baseline designs entail the measurement of behavior under more than one baseline condition and the staggered introduction of a treatment to see if behavior changes only when the treatment is introduced.
For example, consider a study in which a researcher wanted to know whether some treatment decreased SIB in three developmentally disabled adults. Because a reversal design would entail the removal of a potentially effective treatment, which, as I discussed earlier, may carry ethical considerations, a researcher could alternatively use a multiple-baseline design. First, the researcher would measure the “normal” rate of SIB for each subject in the absence of treatment. Once the rate of SIB for each subject had stabilized, the researcher would introduce the treatment for one subject but not the others. Then, at a later point, the researcher would introduce the treatment for a second subject, while the third subject continued under baseline. Finally, the researcher would introduce the treatment for the last subject. If each subject’s behavior changed when—and only when—the treatment was introduced, the researcher could be relatively certain that the treatment, and not some other factor, was responsible for the observed changes (see Figure 10.7).
Summary
The history of psychology is replete with studies in which early, influential researchers examined interesting phenomena using a small number of subjects under tightly controlled experimental conditions. However, the introduction of well-known statistical procedures in the early 20th century led to the emergence of large-N, group-oriented designs, which have exerted a stronghold on psychological research for nearly a century. Nevertheless, single-subject designs continue to provide a viable alternative for researchers wishing to study functional relations and learn more about interesting psychological phenomena. Ultimately, though, which design researchers choose to use in their studies may depend on the specific experimental questions they ask.
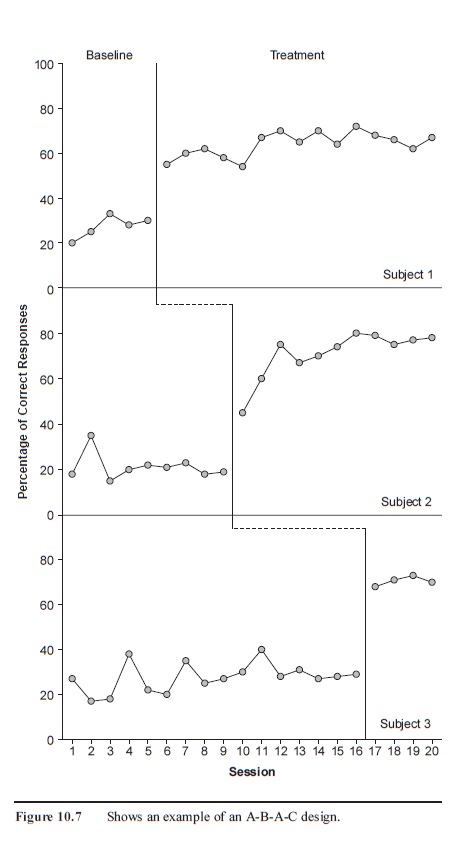 Figure 10.7 Shows an example of an A-B-A-C design.
Figure 10.7 Shows an example of an A-B-A-C design.
References:
- Baer, D. M. (1977). Perhaps it would be better not to know everything. Journal of Applied Behavior Analysis, 10, 167-172.
- Baer, D. M., Wolf, M. M., & Risley, T. R. (1968). Some current dimensions of applied behavior analysis. Journal of Applied Behavior Analysis, 1, 91-97.
- Barlow, D. H., & Hersen, M. (1984). Single case experimental designs: Strategies for studying behavior change (2nd ed.). Boston: Allyn & Bacon.
- Baron, A., & Perone, M. (1998). Experimental design and analysis in the laboratory study of human operant behavior. In K. A. Lattal & M. Perone (Eds.), Handbook of research methods in human operant behavior (pp. 4591). New York: Plenum Press.
- Bickel, W. K., Odum, A. L., & Madden, G. J. (1999). Impulsivity and cigarette smoking: Delay discounting in current, never, and ex-smokers. Psychopharmacology, 146, 447-454.
- Blampied, N. M. (1999). A legacy neglected: Restating the case for single-case research in cognitive-behaviour therapy. Behaviour Change, 16, 89-104.
- Boring, E. G. (1954). The nature and history of experimental control. American Journal of Psychology, 67, 573-589. Boring, E. G. (1957). A history of experimental psychology (2nd ed.). Englewood Cliffs, NJ: Prentice Hall.
- Boyce, T. E., & Hineline, P. N. (2002). Interteaching: A strategy for enhancing the user-friendliness of behavioral arrangements in the college classroom. The Behavior Analyst, 25, 215-226.
- Campbell, D., & Stanley, J. (1963). Experimental and quasi-experimental designs for research. Chicago: Rand-McNally.
- Cook, T. D., & Campbell, D. T. (1979). Quasi-experimentation: Design and analysis issues for field settings. Chicago: Rand-McNally.
- Cooper, J. O., Heron, T. E., & Heward, W. L. (1987). Applied behavior analysis. Columbus, OH: Merrill.
- Crosbie, J. (1999). Statistical inference in behavior analysis: Useful friend. The Behavior Analyst, 22, 105-108.
- Davison, M. (1999). Statistical inference in behavior analysis: Having my cake and eating it? The Behavior Analyst, 22, 99-103.
- Fisher, R. A. (1925). Statistical methods for research workers. Edinburgh, UK: Oliver & Boyd.
- Goodwin, C. J. (2005). A history of modern psychology (2nd ed.). Hoboken, NJ: Wiley. Green, L., &
- Myerson, J. (2004). A discounting framework for choice with delayed and probabilistic rewards. Psychological Bulletin, 130, 769-792.
- Green, L., Fry, A. F., & Myerson, J. (1994). Discounting of delayed rewards: A lifespan comparison. Psychological Science, 5, 33-36.
- Hall, R. V., Lund, D., & Jackson, D. (1968). Effects of teacher attention on study behavior. Journal of Applied Behavior Analysis, 1, 1-12. Johnston, J. M., & Pennypacker, H. S. (1993). Strategies and tactics of behavioral research (2nd ed.). Hillsdale, NJ: Erlbaum.
- Kerlinger, F. N., & Lee, H. B. (2000). Foundations of behavioral research (4th ed.). Orlando, FL: Harcourt.
- Kimble, G. A. (1999). Functional behaviorism: A plan for unity in psychology. American Psychologist, 54, 981-988.
- Loftus, E. F. (1975). Leading questions and the eyewitness report. Cognitive Psychology, 7, 560-572.
- Michael, J. (1974). Statistical inference for individual organism research: Mixed blessing or curse? Journal of Applied Behavior Analysis, 7, 647-653.
- Miller, R. L. (2003). Ethical issues in psychological research with human participants. In S. F. Davis (Ed.), Handbook of research methods in experimental psychology (pp. 127— 150). Malden, MA: Blackwell.
- Mitchell, M. L., & Jolley, J. M. (2004). Research design explained. Belmont, CA: Thomson Wadsworth.
- Myerson, J., Green, L., & Warusawitharana, M. (2001). Area under the curve as a measure of discounting. Journal of the Experimental Analysis of Behavior, 76, 235—243.
- Perone, M. (1999). Statistical inference in behavior analysis: Experimental control is better. The Behavior Analysis, 22, 109—116.
- Rachlin, H., Raineri, A., & Cross, D. (1991). Subjective probability and delay. Journal of the Experimental Analysis of Behavior, 55, 233—244.
- Robinson, P. W., & Foster, D. F. (1979). Experimental psychology: A small-N approach. New York: Harper & Row.
- Saville, B. K., & Buskist, W. (2003). Traditional idiographic approaches: Small-N research designs. In S. F. Davis (Ed.), Handbook of research methods in experimental psychology (pp. 66—82). Malden, MA: Blackwell.
- Saville, B. K., Zinn, T. E., & Elliott, M. P. (2005). Interteaching vs. traditional methods of instruction: A preliminary analysis. Teaching of Psychology, 32, 161—163.
- Saville, B. K., Zinn, T. E., Neef, N. A., Van Norman, R., & Ferreri, S. J. (2006). A comparison of interteaching and lecture in the college classroom. Journal of Applied Behavior Analysis, 39, 49—61.
- Sears, D. O. (1986). College sophomores in the laboratory: Influences of a narrow database of social psychology’s view of human nature. Journal of Personality and Social Psychology, 51, 515—530.
- Sidman, M. (1960). Tactics of scientific research: Evaluating experimental data in psychology. Boston: Authors Cooperative.
- Skinner, B. F. (1938). The behavior of organisms: An experimental analysis. New York: Appleton-Century-Crofts.
- Skinner, B. F. (1966). Operant behavior. In W. K. Honig (Ed.), Operant behavior: Areas of research and application (pp. 12—32). Englewood Cliffs, NJ: Prentice Hall.
- Smith, S., & Ward, P. (2006). Behavioral interventions to improve performance in collegiate football. Journal of Applied Behavior Analysis, 35, 385—391.
- Staats, A. W. (1999). Unifying psychology requires new infrastructure, theory, methods, and research agenda. Review of General Psychology, 3, 3—13.
- Stanovich, K. E. (2001). How to think straight about psychology (6th ed.). Boston: Allyn & Bacon.
- Steele, C. M., & Aronson, J. (1995). Stereotype threat and the intellectual test performance of African Americans. Journal of Personality and Social Psychology, 69, 797—811.
- Sternberg, R. J. (2005). Unity in psychology: Possibility or pipedream? Washington, DC: American Psychological Association.
See also:
Free research papers are not written to satisfy your specific instructions. You can use our professional writing services to order a custom research paper on any topic and get your high quality paper at affordable price.
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality

{kind=link}