
This sample Standard Deviation Research Paper is published for educational and informational purposes only. If you need help writing your assignment, please use our research paper writing service and buy a paper on any topic at affordable price. Also check our tips on how to write a research paper, see the lists of research paper topics, and browse research paper examples.
The standard deviation is found throughout the behavioral and social science literature. It is the average spread among a set of scores around their mean, and it is the most frequently used measure of variability in parametric datasets. Researchers analyze their data by looking at the variability and breaking that variability down into its component parts.
When we describe any set of data we use three characteristics: (1) the form of the distribution, (2) the mean or central tendency, and (3) the variability. All three are required, since they are generally independent of each other. In other words, knowing the mean tells us nothing of the variability.
Variability is a characteristic of all measures. In the social sciences, the people or groups that researchers study may be exposed to the same treatment or conditions, yet they show different responses to that treatment or condition. In other words, all the scores of the people or groups would be different. The goal of the scientist is to explain why the scores are different. If everyone were exactly the same, the standard deviation would be zero.
In addition to describing their data, researchers use the standard deviation in inferential statistics. When they manipulate conditions or treatments, researchers attempt to explain different scores between groups by looking at the variability between the groups. If the groups are different enough, then they are said to be statistically significantly different. This conclusion may be drawn based on the probability (odds) that the difference could have occurred by chance. Researchers use these samples as estimates of the true parameters in the population of interest, and the standard deviation is used (along with the sample size) to establish the precision of the estimates (Winer 1971). The smaller the standard deviation, the smaller the error (or the greater the precision of the estimate).
We also find variability that cannot be explained by the treatments or conditions applied to the people or groups. This variability must also be a part of all the explanations. This part of the variability is often called error, since experiments or studies do not indicate why it occurs.
The English mathematician and statistician Karl Pearson (1857-1936) introduced the procedure and the term standard deviation to statistics in 1892 (Magnello 2005). The standard deviation calculation is very straightforward. The standard deviation is defined as the square root of sum of the squared deviations from the mean, divided by the number of squared deviations. The equation for the standard deviation is
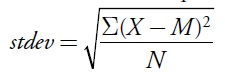 where stdev is the standard deviation, X is a raw score, M is the mean of the scores, X — M represents the deviation of a score from the mean, and N is the number of scores. Many different symbols have been used to represent the elements of the equation, but in all cases the standard deviation is the square root of the average of the squared deviations from the mean.
where stdev is the standard deviation, X is a raw score, M is the mean of the scores, X — M represents the deviation of a score from the mean, and N is the number of scores. Many different symbols have been used to represent the elements of the equation, but in all cases the standard deviation is the square root of the average of the squared deviations from the mean.

At this point, new students of statistics often ask why researchers do not use the deviations from the mean directly. The deviations from the mean cannot be averaged since the sum of the deviations from the mean is always zero. It is possible to use the mean deviation score, which avoids the zero sum by employing absolute values, but this tends to be mathematically cumbersome (Weisstein 2003).
An example will illustrate the calculation of the standard deviation. Let us assume we have five scores for five individuals. The N is equal to 5. The scores are 10, 8, 6, 4, and 2. We must first calculate the mean, so we add all the scores and then divide by N. The sum of the scores (10 + 8 + 6 + 4 + 2) is 30, and the mean is 30 divided by 5, or 6. Next we must subtract the mean from each score to get the deviation score (10 — 6 = 4, 8 — 6 = 2, 6 — 6 = 0, 4 — 6 = —2, and 2 — 6 = —4). Note we cannot get the mean deviation score because the sum of the deviations is zero. This is always true. We solve this problem by squaring each deviation score (which eliminates the negative signs), then summing and dividing by N (42 = 16, 22 = 4, 02 = 0, —22 = 4, and —42 = 16; the sum of these deviation scores squared is 40; dividing 40 by 5 gives us 8). Since this result is the average of the squared deviations (also known as the variance), we must get back to the original score units by taking the square root of 8. The final result is a standard deviation of 2.8284 (rounded to four decimal places). We can say the average spread in the set of scores is about 2.8 (or as precise as we need to be).
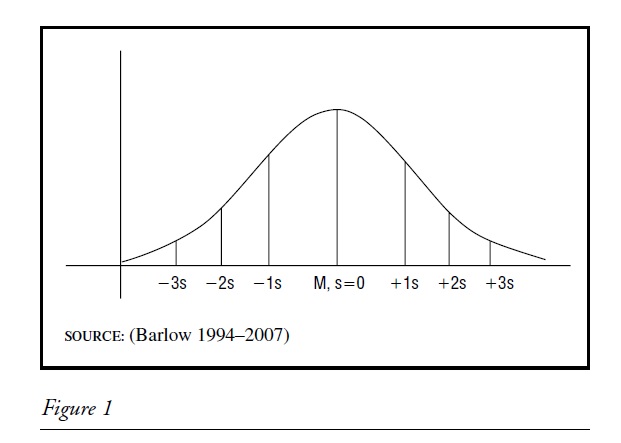
A common way to help students and others visualize the standard deviation is to show a graph of a normal distribution, with the standard deviations as lines above and below the mean. We do this because many variables of interest to science are distributed normally (or approximately so) in the population of interest. In a large distribution (and a population), there are about three standard deviations above the mean, and three below the mean. Given these assumptions, we can say that approximately 68 percent of a population falls between —1 and +1 standard deviation of the normal curve; approximately 95 percent falls between —2 and +2 standard deviations; and better than 99 percent of the population falls between —3 and +3 standard deviations.
When the distribution of scores is not approximately normal, the use of the standard deviation, and the mean itself, may not be the preferred approach for describing the data. The reason for this is that extreme scores will have a large impact on the squared deviations from the mean, making the spread among scores appear quite large.
Skewed population data, such as income, may best be described using the median for central tendency and the mean absolute deviations from the median as the measure of spread. Another approach is to use the semi-interquartile range (also called the interquartile range) to describe the spread in skewed distributions. Extreme scores do not particularly affect this index, but it is more susceptible to sampling fluctuation and should not be used if the distribution is approximately normal. Box plots are often used to show both central tendency and dispersion using the semi-interquartile range. Unfortunately quartiles and box plots do not have the mathematical properties of the standard deviation and limit further analyses.
The standard deviation is used widely throughout the social sciences. In economics, the description of variations in stock prices employs the standard deviation. In political science, the assessment of voter preference is described as a percentage plus or minus, where the plus or minus amount is derived from the standard deviation. In psychology and sociology, variability among individuals and groups is routinely expressed in standard deviation units. In these days of powerful computer-based statistical tools that are available for laptop computers (arguably the two most widely used are SAS and SPSS), obtaining standard deviations (and most other statistical results) is quick and precise. Other programs, designed more for business use, also provide built-in formulas for calculating the standard deviation (often these are not considered accurate for scientific reporting).
Bibliography:
- Barlow, Kathleen. 1994–2007. Standard Deviation. In The Encyclopedia of Educational Technology, ed. Bob Hoffman. http://coe.sdsu.edu/eet/Articles/standarddev/start.htm.
- Games, Paul, and George Klare. 1967. Elementary Statistics: Data Analysis for the Behavioral Sciences. New York: McGraw-Hill.
- Magnello, M. Eileen. 2005. Karl Pearson and the Origins of Modern Statistics: An Elastician Becomes a Statistician. The Rutherford Journal 1 (December).
- http://rutherfordjournal.org/article010107.html. Weisstein, Eric W. 2003. Mean Deviation. MathWorld—A Wolfram Web Resource.
- http://mathworld.wolfram.com/MeanDeviation.html.
- Winer, B. J. 1971. Statistical Principles in Experimental Design. 2nd ed. New York: McGraw-Hill.
See also:
Free research papers are not written to satisfy your specific instructions. You can use our professional writing services to buy a custom research paper on any topic and get your high quality paper at affordable price.
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality


