
This sample Forensic Linguistics Research Paper is published for educational and informational purposes only. If you need help writing your assignment, please use our research paper writing service and buy a paper on any topic at affordable price. Also check our tips on how to write a research paper, see the lists of criminal justice research paper topics, and browse research paper examples.
Overview
Forensic Linguistics is a branch of Applied Linguistics involving the examination of language evidence in a criminal or civil matter and it can be carried out for two broad purposes. First, language analysis can be applied during investigations to assist in the identification of suspects or witnesses, or in determining the significance of utterances or writing to a case. Second, spoken or written language samples may be submitted as evidence in court, along with the testimony of a linguistic expert. Language evidence may bear heavily on the case itself, where the language in question constitutes a language crime: threats, coercion, bribery, hate speech, and hate literature, or language evidence might be more peripherally related to a case and it may necessitate a linguist to clarify the meaning of what is spoken or written, the manner in which it is delivered, and the role of context in the interpretation of the message.
This research paper begins with some historical back-ground, highlighting the first case to which a forensic linguistic analysis was applied. Four areas of practice are exemplified through case reports and the linguistic principles that underpin them: forensic discourse analysis, sociolinguistic profiling, authorship analysis, and forensic phonetics. A discussion of forensic linguists’ roles in investigative and legal processes and the ethics surrounding practitioners’ work concludes the paper.
Origins Of Forensic Linguistics
The term “Forensic Linguistics” is said to have originated with Swedish professor of English, Jan Svartvik, who had examined a set of statements presumed to be a verbatim record of what was said by convicted murderer Timothy Evans during the 1949 investigation into the murders of his wife and infant daughter (Olsson 2004). Svartvik (1968) carefully scrutinized the language contained in four statements collected by police and demonstrated that a significant portion of Evans’ words, particularly those drawn from the confession portions of the statements, were not likely to have been produced by Evans himself. Instead, Svartvik asserted, the investigators had likely added particularly damning information into his statements, which were then submitted as evidence. Svartvik highlights the compelling contrasts between the language likely to have originated with Evans, an illiterate, uneducated man with a low IQ, and language that would be consistent with someone versed in the discourse of law enforcement. The side-by-side comparison below illustrates the disparity.
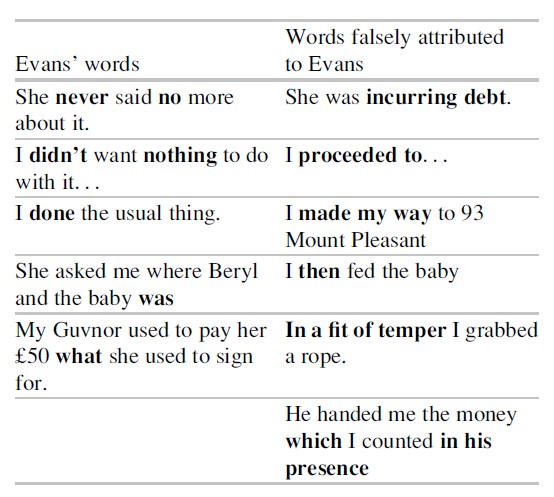
Table 1
Focusing on a few of the qualitative features that Svartvik uncovered, Evans’ language samples contain several features consistent with nonstandard English, including double negatives: “she never said no more about it”; past tense verbs inconsistent with a more standard, educated variety: “I done the usual thing;” and relative clauses headed by relative pronoun “what,” as opposed to “that” or “which.” The words falsely attributed to Evans contained examples of vocabulary and phrasing likely out the range of someone like Evans, for example, “incurring debt,” “proceeded to,” “made my way to” and “in his presence”; and sentence structure containing hallmarks of a more educated speaking or writing style, including adverbs immediately after subjects, relative pronoun “which,” rather than “what.” The differences in sentence structure (syntax) and lexicon (vocabulary) comprised a significant portion of Svartvik’s analysis that would demonstrate how Evans likely did not produce a confession, contradicting the police assertion that they had obtained from him a full confession.
Evans was executed for the murders of his wife and daughter, and would be posthumously pardoned after an inquiry showed that his neighbor, John Christie, had killed the mother and child, along with several others. The case today represents a milestone for the relevance of language evidence.
Forensic Discourse Analysis
The field of discourse analysis is vast, owing to the limitless purposes and contexts for human communication. Forensic Discourse Analysis is applied in cases where the meaning or mode of an utterance has some investigative or legal relevance to a case. Was something someone said a genuine threat? Does a racially tinged utterance constitute hate speech? Was the suicide note found beside a lifeless body written by the deceased or did his murderer write it? At what point in a series of written communications to a target (emails, letters, text messages) does the author exhibit language consistent with stalking? These and numerous other situations have called for linguistic expertise to shed light on language evidence, the meaning of which may be open to interpretation. The types of analyses in FDA touch on speech acts (Austin 1962; Searle 1969); speakers’ cooperation (Grice 1975); turn-taking (Sacks et al. 1974); coherence and cohesion (Halliday and Hassan 1976); and institutional discourse (Drew and Heritage 1992). Two cases are shown below.
Hate Speech And Hate Literature
In many jurisdictions, the law prohibits people from making hateful statements toward a person or people on the basis of race, ethnicity, sexual orientation, religion, gender, or other demographic feature. It is not always certain, however, whether the spoken or written word meets the legal definition of hate speech or hate literature, at which point a linguist might examine the language in question and the context in which it occurs to assist in making that determination.
In Canada, hate speech and hate literature, including Holocaust denial, are illegal.
In the 1990s, a case was brought before the Canadian Human Rights Commission, accusing Ernst Zundel of denying the Holocaust. Zundel, a German national who was living in Canada, disseminated anti-Semitic literature with language that was allegedly consistent with what the Canadian Charter of Rights and Freedoms deems hate language. Gary Prideaux, then a Professor of Linguistics at the University of Alberta, was consulted by the Commission and testified on the linguistic features that qualified Zundel’s prolific work as anti-Semitic and holocaust denying (Prideaux 2011). A small sampling of his analysis is shown on the following passage, taken from Zundelsite (http://www.zundelsite. org/chrc/intervenors.html):
To claim that World War II was fought by the Germans, as the Holocaust Lobby incessantly claims, to kill off the Jews as a group, is a deliberately planned, systematic deception amounting to financial, political, emotional and spiritual extortion. The “Holocaust,” first sold as a tragedy, has over time deteriorated into a racket cloaked in the tenets of a new temporal religion replete with martyrs to the Faith, holy shrines, high priests like Wiesel and Goldhagen, and theologians of the Faith such as Raul Hilberg, Deborah Lipstadt, et al.
Prideaux’s analysis starts with the claim that WWII was fought “by the Germans.. .just to kill off the Jews as a group.” The claimants here, the “Holocaust Lobby,” and the presence of “just” suggests this group holds the simplistic belief that killing Jews was the Germans’ only purpose in the war. Even the verb “claim” entails that the thing claimed is contentious, Prideaux indicates. “Holocaust Lobby” itself is a troubling label suggesting that there exists an organized, centralized group of Jews and Jewish sympathizers “advocating the reality of the holocaust” (p. 42) the reality of which is of course, what Z€undel tenaciously rejects. That the Holocaust be “sold as a tragedy” suggests deception on the part of the “holocaust lobby” which then became an even more malicious movement in the form of a “racket.” Rightfully, Prideaux asserts that “racket” entails a host of negative connotations: “shady, illicit, and negative commercialism, invoking hucksterism and racketeerting” (p. 43), all while cloaked in the accoutrements of religion, again pointing to deceptive, underhanded practices of the target group.
While there is no legislation in Canada equivalent to the United States’ First Amendment guaranteeing freedom of expression, if the spoken or written word targets groups and individuals hatefully, then it is a criminal act, and the speaker or author can be prosecuted. As the passage above shows, the hostility that is apparent on the surface of Z€undel’s writing requires the precision of a linguistic analysis to demonstrate what, in the overall tenor, delivers the hatefulness, in this case Holocaust denial and anti-Semitism, that are both prohibited by law.
Undercover Recordings
Undercover recording is a tool used by law enforcement to aid investigation by capturing key evidence that arises in conversation. Assuming that such recordings are of adequate quality to hear any suspect and cooperating witness or undercover officer, it would seem that this sort of evidence would be very reliable. However, Georgetown linguist Roger Shuy illustrates how what is heard is not necessarily what was said or meant, nor is it necessarily even relevant to the purported criminal action (Shuy 2005).
In Texas v. T. Cullen Davis, the prosecution had relied upon covert recordings of Davis and a cooperating witness, David MCrory, whom Davis had allegedly hired to kill his wife and the judge presiding over their divorce. He also stood trial for the murders of his wife’s lover, and her daughter, and the attempted murder of her as well. McCrory had been an employee in Davis’ company, and he alleged that Davis confessed to the shootings, and that Davis wanted McCrory to kill his wife and the judge. McCrory cooperated with police, and during several interactions with Davis, he wore a hidden recording device. A portion of one conversation is shown below. Bracketed portions represent overlapping speech; italicized portions represent physical movements of the conversants as seen on video surveillance.
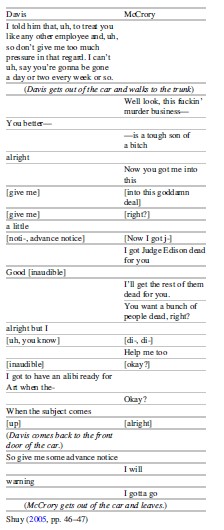 Table 2
Table 2
Using this side-by-side presentation, Shuy was able to demonstrate how Davis and McCrory were speaking about two unrelated topics. Davis was talking about McCrory’s having to account for his absences at work while McCrory was talking about the alleged murderfor-hire. That the two were not addressing the same topic is atypical of natural conversation, because speakers generally adhere to the topic at hand, and the turns are cohesive with one another, meaning that each turn bears some relevance to the turn before it (Halliday and Hassan 1976). The speakers here depart markedly from this principle, evidenced by each maintained his own topic. Davis himself does not in fact utter anything in relation to the killings, nor does he acknowledge what McCrory says about murder. Instead, he remains on the topic of McCrorys’ work absences. He utters “good” and “alright” on the transcript, suggesting concurrence with McCrory’s explicit reference to “getting people dead”; however, “neither was uttered in a response intonation, but rather as low-pitch discourse markers related to his own topic” (Shuy 2005, p. 48). It is not possible to be certain that Davis even heard McCrory, who was inside the vehicle by the time he was uttering what might have been the most damning words about the contract murder. Shuy refers to this as a “hit and run” in covert recordings, where the cooperating witness produces incriminating information while the suspect is either unaware or unable to respond to it. For language to be incriminating, it must be both cohesive with surrounding discourse, and if not from the mouth of the suspect, it must be evident that the suspect is in unambiguous agreement with what is said.
In both of the examples shown above, the linguists used linguistic principles to provide clarity in cases where language evidence was less straightforward than it appeared, and the importance of a thorough understanding of language samples cannot be overstated when the spoken or written word has some bearing in a legal matter. For a more thorough overview of Forensic Discourse Analysis, see Fadden (2012).
Authorship Analysis
In cases where the authorship of a document or set of documents is contentious, a linguist may be asked to opine on the authorship of the disputed writing. This typically entails comparing the disputed sample with samples known to have been written by a particular individual. There are two broad approaches to authorship analysis: linguistic and computational. Each is considered in this section.
Linguistic Approaches To Authorship
First, the linguistic approach, a more traditional approach to language evidence, typically involves a principled selection of qualitative and quantitative analyses comparing one piece of writing with another to rule in or rule out common authorship (see McMenamin 2002 for one systematic approach of this type). Underlying the linguistic approach is the notion of the idiolect (Bloch 1948, p. 7), meaning that “every native speaker has their own distinct and individual version of the language they speak and write” Coulthard (2004, p. 431) While the idea of a linguistic fingerprint unique to each language user is too strong, Coulthard assumes that individuals, with unique vocabularies and preferences for particular combinations and structures, typify the user’s style. McMenamin puts it succinctly: “Unique markers are extremely rare, so authorship [attribution] requires the identification of an aggregate of markers, each of which may be found in other writers.” (McMenamin 2002, p. 172) In other words, while we all have access to the same units and constructs of language, we as speakers have preferences for patterns and they cluster differently from one writer to the next.
Olsson (2004) walks the reader through several worked examples of authorship comparisons. Among his many techniques, Olsson applies the concept of markedness to his analyses. Markedness dates back to the 1930s commencing with Jakobson (see Henning 1989 for historical introduction), who described pairs of linguistic units as having an asymmetrical relationship to one another. The unmarked form is the most frequently occurring, or normal, ordinary form, and the unmarked form is the less frequently occurring, or unusual, irregular form. In the pair happy/unhappy, happy is unmarked, unhappy, with the derivational prefix unis marked. Similarly, in the pair “He had often been seen with her” and “He often had been seen with her,” the former is unmarked, with the adverb often being most commonly positioned between the two auxiliary verbs; the latter is marked, with the adverb often occurring in its less frequently found position before the first auxiliary verb.
In one of Olsson’s authorship cases, anonymous, menacing letters were received by witnesses who were about to testify against the accused in a rape trail. A set of writings known to have originated with the accused were compared to the letters the witnesses turned over to police.
Known Authorship 1: “.. .I was arrested and charged with the rape of Mary. I could not believe this as I am and was impotent.”
Known Authorship 2: “.. .when I was arrested, I was firstly charged with raping Mary, I stated to the Police that I could not rape anyone, as I was impotent, and had been since 1996.”
Unknown Authorship 1: “The good fortune is Joe was able through his solicitors, police forensics and medical reports to prove 100 % that he could not and did not rape or have unlawful sex, through his being Impotent and is and has been for five years or more.”
Unknown Authorship 2: “Neither would have known that Joe, was to enter hospital to have tests to Proving that he is and was impotent.” (Olsson 2004, p. 49)
Given the ordering of the verb pairs on the basis of temporality, i.e., present + past (am/ was; is/has been) or past + further past
 Table 3
Table 3
Olsson concludes the known and unknown texts are likely to have been written by the same author owing to the fact that these verbs appearing in this temporal order represent marked structures, i.e., they occur much less frequently than past + present orderings. Olsson based his conclusion on a number of features in addition to the one described; however, these verb patterns provide a straightforward grammatical example of the type of elements that can be used to match writing samples.
Computational Approaches To Authorship
In recent years, those working at the interface of linguistics and computing science have begun to explore computational means for attributing authorship. Typically, their research focuses on the attribution of authorship in classic works in the humanities and in journalism, but it is not difficult to see the forensic application of computational approaches, in cases where the authorship of a piece of writing is contentious and of legal importance.
Whereas the traditional approaches to authorship involve manual, line-by-line analysis of linguistic features as shown in Olsson’s example above, computing approaches involve mathematical and statistical treatments of the language data, making little or no use of linguistic elements (Juola et al. 2006). The leading approaches in the last decade reduce the documents to unpunctuated strings of letters that are then subject to linear discriminant analysis (Baayen et al. 2002; van Halteren et al. 2005), orthographic cross-entropy (Joula and Baayen 2005); common byte n-grams (Keselj and Cercone 2004), among others (see Juola et al. 2006 for more).
These methods have determined authorship accurately at rates much better than chance. In order to determine the most accurate and effective approaches to authorship attribution, contests are held where teams of researchers are given a set of documents (for example, sets of novels, sets of undergraduate terms papers, a set of letters, or other such corpora for which authorship is already known) and they compete to develop the most accurate system to attribute authorship. One such contest took place at a joint 2004 conference held by the Association for Literary and Linguistic Computing and the Association for Computing in the Humanities, where the most successful team scored an average of 71 % across all of the sample types (see Juola et al. 2006 for an overview of the results and methods, including their own.) While these results are not yet high enough to satisfy the court for forensic determination of authorship, the trends and improvements are encouraging.
Linguistic Or Computational?
The two approaches differ tremendously in that the first is wholly linguistic, where lexical features, syntactic constructions, and even rhetorical devices are examined and compared and the expert renders a conclusion regarding a match in the authorship of compared documents, a nonmatch, or inconclusive results. The second makes no use of linguistic features; rather letters or words are reduced to strings that are compared for similarity on the basis statistical measures.
Members of the International Association of Forensic Linguists, the professional association for linguists and law scholars concerned with language and law, have begun to address the merits of each approach (Solan 2011). Whereas traditional authorship attribution methods have been admitted in UK and US courts, Solan points out that at least for US jurisdictions, they do not meet the strict criteria set out by Daubert and Frye standards, specifically that the error rates of such methods are not known. Computational methods lend themselves well to meeting such criteria; however, current technology has not reached a satisfactory level for forensic identification.
Sociolinguistic Profiling
In the 1960s, William Labov introduced the linguistic variable, which accounts for why we have accents and why social factors like gender and cultural affiliation can contribute to our using language slightly differently from one another. As speakers, we belong to speech communities, meaning within a geographic area, we share many linguistic similarities, i.e., we share an accent. West coast English in the USA, for example, differs from East coast, northern varieties differ from southern varieties, and differences are found between rural and urban communities. The variation is not limited to geographic bounds. Ethnic and racial communities exhibit their own varieties: The English spoken by blacks and whites in the USA varies (Labov 1966; Shuy 1967). Aboriginal varieties of English are noted in Canada, the USA, and Australia (Fadden and LaFrance 2010; Scollon and Scollon 1979; Butcher 2008, etc.) There are differences found between young and old, male and female, and variation is distributed across socioeconomic lines, as well as linguistic variation noted between occupations, where specific vocabulary and phrasing serves the group in the commission of their jobs (see Wardhaugh 1986 for a comprehensive introduction in sociolinguistics). All of these noted variations can be useful clues to narrow down the suspect pool.
In a 2010 “poison pen letter” case, the board of directors and the executive team of a large Canadian company received a disturbing letter from someone claiming to be a staff member in the company. In the letter, the individual listed numerous complaints about the company, including nepotism, favoritism, and poor management. The company’s legal team asked one of the present authors to determine who, within the organization, could have written the letter.
While it is not possible to identify the precise individual on the basis of linguistic features, it was possible to assert that the author was positioned at the upper end of the company hierarchy rather than at the lower, service end.

The following excerpts show how the author had portrayed himself as part of a group of lower management and service staff addressing a variety of issues that would pertain to that portion of the company’s workforce.
 Table 4
Table 4
The examples above might well have originated with a staff member who deals directly with customers. However, other features strongly suggest that the letter was written by someone who does not work at the service side of the business, but rather someone on the executive side. The following examples address concerns that would not fall within the domain of a service side employee.
 Table 5A
Table 5A
 Table 5B
Table 5B
It is unlikely that a low ranking staff member or even a low-level manger would have cause to comment on matters concerning the funding of projects, company cash flow, and capital. Nor does it seem likely that the same individual would make pointed criticism of the company executive because there would not likely be occasion for him to meet, much less work with VPs and the CEO to form opinions about their character.
The author further casts suspicion on his purported low-level position in the company in the following passage:
Our managers are unwilling to deal with the worst of the staff knowing they will get little support form [sic] head office and will likely end up defending themselves from whatever accusation is thrown at them.
Personal pronouns (they, them) and reflexive pronoun (themselves) used in this sentence strongly suggest his exclusion from the group, and betray the author’s claimed identity. The author of the letter was in fact a former vice president who had been forced to resign, and he had written anonymously to the board of directors and the executives to harass and embarrass the CEO.
Sociolinguistic profiling is carried out on language evidence and the linguist constructs an informed opinion on the basis of observable linguistic features. As with other types of profiling, it is an inexact science, because no subject will exhibit all features of their type, and subjects may exhibit features inconsistent with their type. The writer may also attempt to mask features, as the corporate letter case above demonstrates. However, the features to be found in our speaking or writing can in fact provide clues to our demographics. Alone or in combination with psych profiling, sociolinguistic profiling can be very useful when identifying suspects or witnesses at the outset of an investigation.
Phonetics In Criminal Cases
Where language evidence is spoken, phoneticians – that is, linguists specializing in the acoustics and articulation of the spoken word – may lend their expertise.
But forensic interest in the spoken word long predates the science of phonetics. Voice identification by earwitnesses has been admitted at trials dating back at least to the seventeenth century, when William Hulet was accused of having served as the executioner of King Charles I of England. Though masked on the scaffold, Hulet had been recognized by a witness solely “by his speech.” This evidence – along with little else, mostly hearsay – resulted in Hulet being found guilty of high treason.
Another high-profile case involving voice identification, the Crime of its own Century, centered on the 1932 kidnapping of the young son of aviator Charles Lindbergh. Lindbergh, who had only heard six words uttered by his son’s abductor, initially told a grand jury that “[i]t would be very difficult to sit here and say that I could pick a man by that voice”. But at trial, nearly 3 years after hearing the voice of the abductor, Lindbergh went on to identify it as that of suspect Bruno Hauptmann. A year after Hauptmann was executed for this crime, the results of a voiceidentification experiment shed light on some of the issues raised during the trial (McGehee 1937). Subjects were asked to pick out a previously heard target voice from a lineup of five similar voices. After an interval of 1 day, and even 1 week, subjects were able to identify the target voice with more than 80 % accuracy, but by 2 weeks that figure had dropped to 69 %, and by 3 weeks to 51 %. By 5 months, recognition had descended to chance level. This suggests some limitations to voice identification, unless a suspect is apprehended in short order, or the unknown voice is captured on a recording.
In 1962, an article in the journal Nature described a new and objective procedure for identifying voices with reportedly astonishing accuracy (Kersta 1962). The technology was not new, having been developed (under the name “sound spectrography”) as part of the World War II effort to track German troop movements. The methodology – essentially pattern-matching among printouts of vocal energy – was based on a “theory of invariant speech,” which claimed that each person’s voice pattern is unique. (Little scientific support was ever offered for this theory, and it was soon undermined by studies involving vocal disguise.) Notably, the author of that article discarded the old name for the physical record of sound spectrography (“sound spectrograms”), and instead coined the word “voiceprints,” which implied a level of reliability similar to that of fingerprints.
However, phoneticians (notably Professors Peter Ladefoged of UCLA and Harry Hollien of the University of Florida) argued strenuously that “voiceprints” of the highly mutable and continually shifting human voice are not nearly as reliable as fingerprints. The former are graphic representations of the energy produced by fluid articulatory gestures (such as the rounding of the lips and the raising of the tongue) which can occur simultaneously, sequentially, or not at all; the latter are direct physical impressions of digital topography, and are immutable.
Not long after the publication of the Nature article, the “voiceprint” technique began to be used by prosecutors in criminal cases. It was immediately challenged on the basis of not having gained general acceptance in the scientific community. Different jurisdictions reached different conclusions in this regard. However, within a few decades, Kersta’s original methodology – mere pattern-matching, without even the need to listen – had been all but abandoned.
But a growing body of research has demonstrated that the acoustic information present in sound spectrograms, when interpreted in the light of phonetic principles, can indeed enhance the auditory identification of voices. Some robust results have been reported for lengthy voice samples. And even voice samples of moderate size can derive benefit from phonetic analysis.
Additionally, if two speech samples are lengthy enough to be compared in considerable detail, one may be able to evaluate the strength of the evidence in the form of a “likelihood ratio.” Numeric ratios of this sort can be assigned verbal values, such as “very strong evidence [to support the hypothesis of speaker identity],” “strong evidence,” “moderately strong evidence,” etc., and presented to the trier of fact.
Some of the phoneticians who had initially been most critical of the forensic use of sound spectrograms came to moderate their views, once those spectrograms were no longer associated with a superficial pattern-matching technique and no longer bore the unduly suggestive name “voiceprints.” Ladefoged, for one, did so while advocating procedural safeguards such as sufficient length (far exceeding the FBI standard), clarity (a signal-to-noise ratio where the signal is higher by 20 dB), and frequency range (at least 3,000 Hz). Under good conditions, he later wrote, “virtually all phoneticians would agree that acoustic phonetic analyses have some evidential value” (Ladefoged 1982).
One example of a phonetic analysis that was considered to have evidential value was that presented at the trial of Paul Prinzivalli, who was accused of phoning in 25 separate bomb threats to Pan American World Airways in 1984. Prinzivalli, a disgruntled Pan Am employee, had been identified as the suspect by two senior supervisors – though his immediate supervisor disagreed, pointing to differences in the “inflection, accent, tone, depth, pronunciation, timbre” of his voice. The police nevertheless charged Prinzivalli with having made the bomb threats, and he faced a possible 6–8 years in prison.
Sound spectrograms of the would-be bomber’s words and of Prinzivalli’s exemplar of those same words displayed numerous differences. The lower vocal resonances, which mainly indicate which words are spoken, differed in a way that suggested the presence of two different accents. The upper vocal resonances, which can provide evidence of speaker identity, were attenuated, but still suggested the presence of two different individuals. In particular, the fourth resonance, where visible, did not match across conditions. And the third resonance closely tracked the rises and falls of the second resonance in the voice of the suspect, but remained high and steady in the voice of the would-be bomber.
These differences, presented in court by Ladefoged and by one of the present authors, were corroborated by a dialect study conducted by William Labov of the University of Pennsylvania, the author of numerous books on this topic, including the authoritative Atlas of North American English. Labov concluded that the unknown voice was a Bostonian, whereas the suspect was a lifelong New Yorker.
The judge found Prinzivalli not guilty, calling the linguistic evidence “objective” and “powerful.”
Automatic Analyses
When an abundant amount of speech is available for analysis, the “auditory-acoustic” method described above may be supplanted by a computerized system that does not examine individual phonetic parameters at all. Instead, such “automatic” systems treat the speech sample as a single, continuously varying complex vibration, which can be modeled mathematically and then compared to another speech sample. “Automatic” methods of analysis are usually quite accurate, but they typically have a high rejection rate (otherwise associated with short samples, or with noisy samples of moderate length). In general, the optimal methodology will be dictated by the length and the quality of the speech signal.
Phonetics In Trademark Disputes
The phonetic methodology described above can also be employed in the resolution of trademark disputes. According to US law, trademark infringement may occur when two marks denoting similar products or services are sufficiently similar to cause confusion (or potential confusion) among consumers. When infringement is determined to have occurred, the newer (“junior”) mark must give way to the senior mark. But there is often controversy over what constitutes “sufficient” similarity. What may seem misleadingly similar to one party may seem quite distinct to another.
The situation is difficult enough to resolve when it is limited to orthography and to related issues of trade dress such as the color and font of the mark. It becomes even more difficult for experts when sounds are taken into consideration.
A manufacturer may specify the intended pronunciation of a newly coined trademark directly on the package, or in a source such as the Physician’s Desk Reference, or through advertising in broadcast media. But it is by no means clear whether the public will accept (or even notice) such specification, or instead fall back on the familiar rules of spelling. Such a dispute was, for example, at the heart of trademark litigation between the manufacturers of competing birthcontrol pills, OVRAL and B-OVal (Shuy 2002). The manufacturers of OVRAL maintained that their trademark name was to be pronounced with final stress (o-VRAL, to rhyme with go-ALL). However, final stress is not very common in English words. A reverse-order (or “rhyming”) dictionary shows that, of almost 2,000 multisyllabic English words ending in –al, only about a dozen bear final stress.
A growing body of evidence shows that knowledge about such preferences, along with other spelling-to-sound relationships of the English language, is represented in the mind of the reader and is called upon when necessary, such as when words are encountered for the first time (Treiman et al. 2002). This can even help us to read nonce words, such as those in Lewis Carroll’s poem Jabberwocky. But such rules can be a powerful counterweight to the trademark holder’s intentions, and may indeed result in consumer confusion.
Litigants often commission consumer surveys to determine the likelihood of consumer confusion, but such surveys must be carefully crafted to avoid suggestiveness, and to adequately sample the marketplace.
As an alternative, or a supplement, to such surveys, litigants have called upon linguists to present any phonetic facts that might give rise to, or else rule out, the likelihood of consumer confusion. A linguist trained in phonetics can call attention to any articulatory or acoustic similarities that might exist between the sounds of two trademark names. The use of the International Phonetic Alphabet can override the vagaries of English spelling (such as orthographic “qu,” which, despite appearances, is not a consonant-vowel sequence). And a table of documented misperceptions, a staple of the psycholinguistic literature, can suggest which of all possible pairs of sounds are most likely to be confused by the consumer.
All of the above arguments were made by one of the present authors in trademark litigation between two competing mortgage companies, Ameriquest and Americrest. Evidence from phonetics (articulatory lip rounding, acoustic overtone patterns, and the International Phonetic Alphabet) and from psycholinguistics (listeners’ documented tendency to confuse the distinguishing letters of these trademarks under laboratory conditions – in this case a 28 % confusion rate, even without advertising jingles playing in the background) were offered as arguments for the potential confusability of these two marks. The case was promptly settled.
Forensic Linguistics And Ethics In The Legal System
As more linguists find themselves consulted by law enforcement and legal counsel on cases involving language evidence, the Linguistic Society of America compiled a four-part statement of ethics to which linguists are expected to adhere. First, a consulting linguist must act with professional integrity: He or she is to provide an objective analysis and compensation cannot be dependent on the outcome of any findings. Second, there must be transparency regarding the methodology used, as well as a clear account of any data, equipment, statistical tests, and software used. The linguist must also make clear any known limitations of the aforementioned and his or her own abilities. Third, the linguist must not disclose any confidential information relating to his or her casework without the consent of affected parties. Any research arising from casework should be anonymized such that there is no identifiable information appearing in presentations or publications. Furthermore, the linguist must not take on casework that can result in a conflict of interest, nor should she or he communicate informally or unofficially with an opposing party’s linguist or legal counsel. Fourth, linguists are strongly encouraged to communicate that they abide by the Code of Ethics passed by the Linguistic Society of America if practicing within the USA, although others are free to subscribe to this code as well. Furthermore, linguists are encouraged to abide by the codes agreed upon by any other professional organizations such as the International Association of Forensic Linguists and the International Association of Forensic Phoneticians.
Linguistics, like most other social sciences, is a wide field with a variety of subfields, and, as a discipline, is taught in many university campuses. Many research universities offer doctoral in linguistics. In American and UK courts, it is largely the decision of the trial judge to admit (or not) a linguist and his or her testimony, and it appears to be happening with greater frequency as the usefulness of linguistic analysis is understood.
Bibliography:
- Austin JL (1692) How to do things with words. Harvard University Press, Cambridge
- Baayen RH, van Halteren H, Neijt A, Tweedie F (2002) An experiment in authorshihp attribution. In: Proceedings of JADT 2002, Universite´ de Rennes, St. Malo, pp 29–37
- Bloch B (1948) A set of postulates for phonemic analysis. Language 24:3–46
- Butcher A (2008) Linguistic aspects of Australian Aboriginal English. Clin Linguist Phonet 22:625–642
- Cambier-Langeveld T (2007) Current methods in forensic speaker identification. Int J Speech Lang Law 14 (2):223–243
- Coulthard M (2004) Author identification, idiolect, and linguistic uniqueness. Appl Linguist 25(4):431–47
- Coulthard M, Johnson A (2007) An introduction to forensic linguistics: Language in evidence. Routledge, London
- Criminal Code, R.S. c. C-46 (1985) Retrieved from http://laws.justice.gc.ca/en/C-46/index.html. Accessed 11 June 2013, 11:14 PST
- Drew P, Heritage J (eds) (1992). Talk at work: interaction in institutional settings (Studies in interaction sociolinguistics, 3 edn). Cambridge University Press, Cambridge
- Fadden L (2012) Forensic discourse analysis. In Chapelle C (ed) The encyclopedia of applied linguistics. WileyBlackwell, Malden
- Fadden L, LaFrance J (2010) Advancing aboriginal English. Can J Native Education 32
- Grice HP (1975) Logic and conversation. In Jaworski A, Coupland N (eds) The discourse reader. Routledge, New York, pp 76–87
- Henning A (1989) Markedness – The first 150 years. In Tomic O (ed), Markedness in synchrony and diachrony. Mouton de Gruyter, Berlin, pp 11–46
- Halliday M, Hasan R (1976) Cohesion in English. Longman, London
- Joula P, Baayen H (2005) A controlled-corpus experiment in authorship Identification by cross-entropy. Lit Linguist Comput 20(Suppl 1):59–67
- Juola P, Sofko J, Brennan P (2006) A prototype for authorship attribution Software. Lit Linguist Comput 21:169–178
- Kersta L (1962) Voiceprint identification. Nature 196:1253–12857
- Keselj V, Cercone N (2004) CNG method with weighted voting. Ad-Hoc Authorship Attribution Contest ACH/ ALLC. Gothenburg, Sweden
- Kreiman J, Sidtis D (2011) Foundations of voice studies. Wiley-Blackwell, Malden
- Labov W (1966) The linguistic variable as a structural unit. Washington Linguist Rev 3:4–22
- Labov W, Ash S, Boberg C (2005) Atlas of North American English. de Gruyter, Berlin
- Ladefoged P (1982) A course in phonetics. Harcourt Brace Jovanovich, San Diego
- Ladefoged P (1984) Review: the phonetic bases of speaker recognition by F.J. Nolan. J Phonet 12:85–89
- Ladefoged P, Disner S (2012) Vowels and consonants. Wiley-Blackwell, Malden
- McGehee F (1937) The reliability of the identification of the human voice. J Gen Psychol 17:249
- McMenamin G (2002) Forensic linguistics: advances in forensic stylistics. CRC Press, London
- Morrison G (2010) Forensic voice comparison. In Freckelton I, Selby H (eds), Expert evidence (Ch. 99). Thomson Reuters, Sydney, Australia
- Morrison G (2009) Forensic voice comparison and the paradigm shift. Sci Just 49:298–308
- Olsson J (2004) Forensic linguistics: an introduction to language, crime, and the law. Continuum, London
- Prideaux G (2011) Linguistic contributions to the analysis of hate language. Int J Law Lang Discourse 1(1):27–52
- Sacks H, Schegloff, Jefferson G (1974) A simplest systematics for the organization of turn-taking for conversation. Language 50(4):696–735
- Scollon R, Scollon S (1979) An ethnography of speaking at Fort Chippewyan, Alberta. Academic, New York
- Searle J (1969) Speech acts: an essay in the philosophy of lanaguage. Cambridge University Press, Cambridge
- Shuy R (1967) Discovering American dialects. National Counsel of Teachers of English, Champaign
- Shuy R (2002) Linguistic battles in trademark disputes. Palgrave Macmillan, New York
- Shuy R (2005) Creating language crimes: how law enforcement uses (and misuses) language. Oxford University Press, New York
- Solan L (2011) Ethics and method in forensic linguistics. In Tomblin S, MacLeod N, Sousa-Silva R, Coulthard M (eds), Proceedings of the international association of forensic linguists’ 10th biennial conference. Centre for Forensic Linguistics, Aston
- Svartvik J (1968) The Evans Statements: a case for forensic linguistics. University of Gothenburg Press, Gothenburg
- Treiman R, Kessler B, Bick S (2002) Context sensitivity in the spelling of English vowels. J Mem Language 47:448–468
- van Halteren H, Baayen RH, Tweedie F, Haverkort M, Neijt A (2005) New machine learning methods demonstrate the existence of a human stylome. J Quant Linguist 12(1):65–77
- Wardhaugh R (1986) Introduction to sociolinguistics, 2nd Blackwell, Cambridge
See also:
Free research papers are not written to satisfy your specific instructions. You can use our professional writing services to buy a custom research paper on any topic and get your high quality paper at affordable price.
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality

{kind=link}