
This sample Vision Research Paper is published for educational and informational purposes only. If you need help writing your assignment, please use our research paper writing service and buy a paper on any topic at affordable price. Also check our tips on how to write a research paper, see the lists of psychology research paper topics, and browse research paper examples.
The physical properties of light make it an ideal source of information about the external world. Light is a form of energy emitted by the sun and artificial sources, such as lamps, and travels virtually instantaneously in straight lines, or rays. When light rays encounter an obstacle they may be transmitted, absorbed, or reflected. All three behaviors are important for vision:
- During transmission through translucent objects, the rays may change direction (refraction), a crucial property of lenses.
- Absorption by photoreceptors in the eye is necessary for the process of vision to begin.
- Reflection from an opaque surface provides visual information about its properties—its material substrate, shape, and position.
Paradoxically, light behaves as a particle as well as a ray. Light particles (photons) have a vibration frequency, or wavelength, which is important for color vision.
The eye is an optical instrument similar to a simple camera. A bundle of light rays strikes the cornea (trans-parent front surface of the eye) and enters the eye through a small aperture (the pupil). The rays pass through a lens and strike the network of cells lining the inner surface of the eyeball (the retina). Due to refraction of the rays by the cornea and the lens, an image of the external world is formed on the retina (see Figure 23.1).
Although the retina of the eye contains an image of the world, the image itself is not intended to be seen. We see the external world before our eyes, not the retinal image inside our eyes. Patterns of neural activity initiated by the retinal image lead to conscious visual experiences that are selective, incomplete, and sometimes inaccurate. An artist paints what he perceives, not his retinal image. Nevertheless, the artist’s perception is intimately linked to the information available in the visual world, and to the neural apparatus that processes it.
Vision As Information Processing
Luminous intensity in the bundle of light rays passing through the lens varies as a function of spatial position, normally specified in terms of x (horizontal position) and y (vertical position), to build a two-dimensional retinal image. In a dynamic natural environment, image intensity also varies as a function of time (t) and light wavelength (X). One must also take account of the slight difference in viewing position between the two eyes, which can create small differences in retinal luminance, position, and speed as a function of eye-of-origin (e). All the binocular information available for vision can thus be encapsulated in a function containing five parameters: x, y, t, X, and e. It is the task of the visual system to derive from this retinal luminance function a meaningful representation of the layout and disposition of the surfaces and objects in view. The task is an immensely complex one, as can be inferred from the limited capabilities of artificially created visual systems in computer vision systems. It is, above all, an information-processing task.
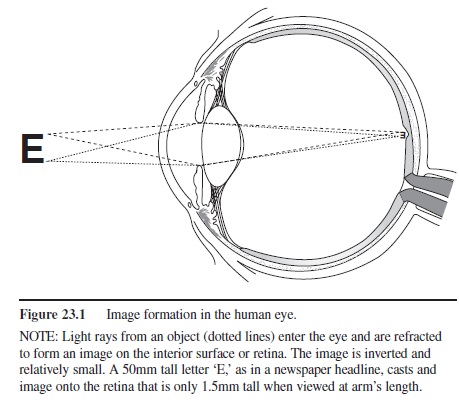 Figure 23.1 Image formation in the human eye.
Figure 23.1 Image formation in the human eye.
NOTE: Light rays from an object (dotted lines) enter the eye and are refracted to form an image on the interior surface or retina. The image is inverted and relatively small. A 50mm tall letter ‘E,’ as in a newspaper headline, casts and image onto the retina that is only 1.5mm tall when viewed at arm’s length.
Theory
Information-processing Theory: Representation and computation
Visual stimulation generates electrical activity along the neural pathways from eye to brain. Neuroscientists assume that there is a causal link between this activity and perceptual experience. The neural signals pass through a series of processing stages, embodied in large populations of neurons in the brain, to build internal representations of visible surfaces and objects. Each stage of processing can be conceptualized as an information-processing device. Figure 23.2a shows a simple information-processing device containing three elements: an input, a “black box” processor, and an output. Operations performed by the processor convert the input into the output. The visual system as a whole can be considered to be an information-processing device (Figure 23.2b). The input is the retinal image, and the output is a perceptual event, such as recognition of an object. The black box contains the neural processes that mediate this event. What goes on inside the information-processing black box? Two concepts, representation and computation, are crucial to modern conceptions of visual information processing. The state of one physical system can stand for, or represent, the state of another system. For example, the reading on a thermometer may represent ambient temperature, or the display on a vehicle’s speedometer may represent its speed. In the case of vision, a specific pattern of neural activity may represent a specific property of the visual world, such as the brightness of a light, the speed of a moving object, or the identity of a face. The information-processing device in Figure 23.2 contains representations created by computations performed on its input. Computation involves the manipulation of quantities and symbols according to a set of rules or algorithms. Any device that takes an input and manipulates it using a set of rules to produce an output can be considered to be a computational device. The visual system is such a device. In order to understand vision, we must understand the representations that are formed in the visual system, and the computations that transform one representation into another.
A large complex problem can be made more tractable by breaking it down into smaller problems. As illustrated in Figure 23.2c, research has shown that the visual system as a whole can be broken down into sub-systems. Some subsystems operate in series, so the output of one stage feeds the next stage, and other subsystems operate in parallel. Each subsystem can be considered as a self-contained module of processing devoted to a specific computational task. Signals and computations can be represented in mathematical form as a matrix of numbers, or as a mathematical function. Certain mathematical theories have proved to be especially useful for understanding the computations performed by the visual system.
Linear Systems Theory
One way to characterize the properties of an information-processing device would be to measure its response to all possible inputs. In the case of the visual system, this is an impossible task because the number of possible input images that could impinge on the system is unlimited. If the system can be considered a linear system, then it is possible to adopt a simpler approach: measure the responses to a small set of inputs and predict the response to any input. The most commonly used simple visual input is a sinusoidal grating, a regularly repeating pattern of alternating light and dark bars. In order to qualify as a linear system, the visual system’s response must obey certain rules. First, if the magnitude of the input changes by a certain factor, then the response must change by the same amount. For example, if the grating doubles in contrast, then the magnitude of response must double. Second, the response to two gratings presented together must be equal to the sum of the responses to the two gratings when presented separately. Third, if the grating shifts in position, the response should not change except for the shift in position. The distance between adjacent bars in the grating (the grating period) should be identical in the input and the output. If all these rules are satisfied, the system qualifies as a shift-invariant linear system.
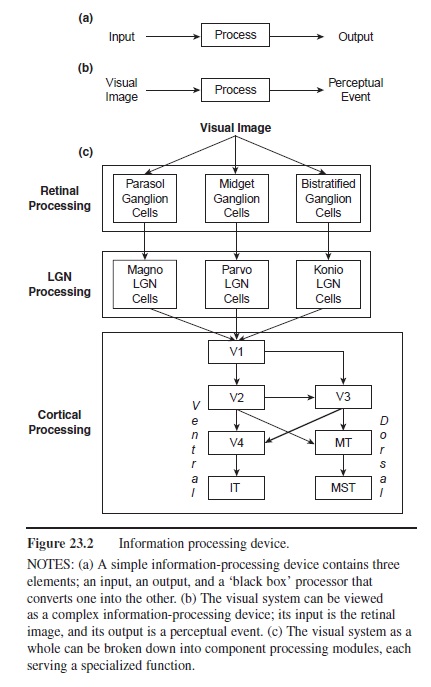 Figure 23.2 Information processing device.
Figure 23.2 Information processing device.
NOTES: (a) A simple information-processing device contains three elements; an input, an output, and a ‘black box’ processor that converts one into the other. (b) The visual system can be viewed as a complex information-processing device; its input is the retinal image, and its output is a perceptual event. (c) The visual system as a whole can be broken down into component processing modules, each serving a specialized function.
Sinusoidal gratings are special stimuli, according to a mathematical theory called Fourier theory—any complex image can be considered to be a collection of sinusoidal gratings. So once we know how a linear system responds to individual gratings, we can predict its response to any image.
Research has shown that the visual system qualifies as a linear system only in certain restricted conditions. However, the linear systems approach offers a powerful tool for studying the early stages of processing, and for specifying how and when nonlinearities intrude on the system’s behavior.
Bayesian Inference
Although linear systems theory is extremely useful for understanding the early stages of visual processing, its utility is more limited when one considers higher levels of processing. Linear systems restrict themselves to the information available in the input, and never extrapolate beyond the available information. But it has become clear that for many visual tasks there is insufficient information available in the input to arrive at a unique solution. For example, the projection of a solid object onto a 2-D image is ambiguous, because many different objects could all potentially project the same image. Does the object in Figure 23.3 have a trapezoidal shape, or is it a rectangle viewed from an oblique angle?
The visual system must go beyond current information and draw inferences based on context, experience, and expectation. Theories of vision have long since acknowledged the need for perceptual inferences, but only relatively recently has another mathematical tool, Bayesian statistics, been brought to bear on the issue. In Bayesian statistics available data is used to infer the probability that a specific hypothesis may be true. A Bayesian inference is called a posterior probability—the probability that a particular conclusion is valid (e.g., that the shape is rectangular). It is calculated using two other probability values—a prior probability of the likelihood of encountering rectangular shapes in the world, and a conditional probability that the image in view could have arisen from a rectangular shape. Bayesian inference encapsulates knowledge of the world in prior probabilities, and sensory data in conditional probabilities. It offers a rigorous mathematical method for evaluating whether the visual system is making optimal use of the information available.
Psychophysical Theory
Visual stimuli are defined in physical terms such as size, intensity, contrast, or duration. They evoke perceptual experiences such as “red,” “bright,” or “fast.” What is the relation between physical stimuli and perceptual experience? Experiments to investigate this relation (known as psychophysical experiments) measure the detectability or discriminability of simple visual stimuli as a function of a physical stimulus parameter. Data invariably show a gradual transition between one category of response and another. For example, to measure sensitivity to light the experimenter may manipulate the intensity of a light stimulus, and the task of observers is to report whether they can detect the light or not. A plot of the probability of detection as a function of stimulus intensity (psychometric function) should show a gradual shift from no-detection to detection as the stimulus level increases. Classical psychophysical theory (see Chapter 20) explained the smooth function by assuming that the observer’s visual system has an internal threshold stimulus value, below which the stimulus is never detected and above which it is always detected. Moment-to-moment fluctuations in this threshold introduce a degree of uncertainty in the observer’s responses, creating the smooth curve. Classical theory took no account of other factors that can bear on the observer’s decision and add a bias to his or her responses, such as motivation and confidence. Classical theory has therefore been superseded by Signal Detection Theory, according to which participants’ decisions are determined jointly by their sensory response and by a bias or tendency to respond in a certain way. Experimental methods used in modern psychophysical research involve techniques that take account of the possibility of bias in observer responses.
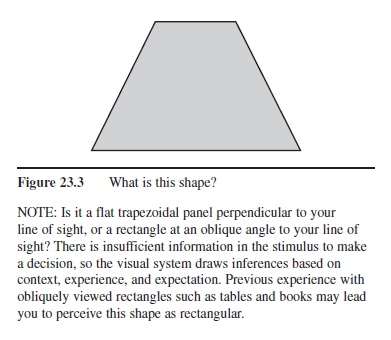 Figure 23.3 What is this shape?
Figure 23.3 What is this shape?
NOTE: Is it a flat trapezoidal panel perpendicular to your line of sight, or a rectangle at an oblique angle to your line of sight? There is insufficient information in the stimulus to make a decision, so the visual system draws inferences based on context, experience, and expectation. Previous experience with obliquely viewed rectangles such as tables and books may lead you to perceive this shape as rectangular.
Methods
Psychophysics
Psychophysics is the scientific study of the relation between physical stimuli and perceptual phenomena. Modern empirical research on vision is dominated by psychophysical experiments that measure an observer’s ability to detect very weak visual stimuli, such as low-contrast or slowly moving patterns, or to discriminate between two very similar stimuli, such as two patterns differing slightly in contrast or direction. Carefully designed, well-controlled psychophysical experiments can be used to test the predictions of specific computational theories, and can be compared against the results of neurophysiological experiments.
The techniques used in psychophysical experiments were first developed in the late nineteenth century by Gustav Fechner. Psychophysical experiments offer an important perspective on human visual capabilities. However, a more complete understanding of vision also requires that we consider two other perspectives, computational modeling and neurophysiology.
Computational Modeling
As outlined in Figure 23.2, the visual system can be viewed as a hierarchically organized system of information-processing devices. Each device computes an output from a given input, based on a set of transformation rules or algorithms. The precise characteristics of the system can be defined mathematically, and can be implemented on a computer. In principle, then, it should be possible to implement certain aspects of visual function on a computer. Indeed there have been many attempts to build computer vision systems, either to replace a human operator in dangerous environments or as a way of testing theories of human vision. In the latter scenario, the first step in computational modeling is to devise a model that is consistent with available empirical data, and that completes its task successfully. Then the model can be made to generate pre-dictions for the outcome of new experiments, which can be tested psychophysically or neurophysiologically.
Although the theoretical foundations of computational modeling in cognition were laid by the English mathematician Alan Turing in the 1930s, computational modeling become a significant theoretical movement in vision science only during the last twenty years of the 20th century. The change was largely due to the theoretical work of David Marr, a computer scientist who was the first to attempt a comprehensive computational theory of human vision. Though some details of Marr’s theories have been rejected on empirical grounds, the general computational strategy is still accepted as a valuable approach to understanding vision.
Neurophysiology
Physiological studies of the functioning of brain pathways mediating vision have predominantly used the single-unit recording technique. A very fine, insulated electrode is inserted into the visual system of an awake, anesthetized animal. Visual stimuli are presented to the animal, and resulting neural activity is picked up by the electrode and recorded on a data logger or computer. The electrode can be inserted at any point in the visual pathway, from retina to cerebral cortex. Recordings reveal the stimulus-dependent response of the cell closest to the electrode.
The single-unit recording technique was developed in the 1950s by Stephen Kuffler and Horace Barlow, who recorded activity in the cat and frog retina, respectively. It was used by David Hubel and Torsten Wiesel in the late 1950s and early 1960s to record activity in cat and monkey cerebral cortex.
During the last 15 years brain imaging has emerged as an important technique for studying the functional organization of the human visual system. The subject is placed bodily in the brain scanner and presented with visual stimuli. In functional MRI scanners, short bursts of radio waves are passed through the brain at many different angles (also see Chapter 16). Neural activity evoked by the stimuli causes tiny changes in the magnetic properties of blood hemoglobin, which are detected and processed to build up a picture of the brain areas activated. The number of functional MRI scanning studies has grown exponentially since the first papers appeared in the early 1990s (exponential growth is typical of scientific research in an expanding field). Brain scans are particularly useful for tracing the brain areas activated by particular kinds of visual stimulus, and can even be used to measure visual adaptation effects.
Empirical Results And Inferences
Empirical studies of vision fall into camps: neurophysiological experiments and psychophysical experiments. Modern empirical research is tightly coupled to computational theories, so in the following sections empirical results and relevant theory are presented together.
Neurophysiology
Functional Organization
The visual system includes the retinas, the visual pathway connecting the retinas to the brain, and the visual cortex (Figure 23.4). Each retina contains over 100 million photoreceptor cells divided into two classes, rods and cones. Rods are much more numerous than cones but respond only at the low light levels typical of nighttime. Cones respond during daylight, and can be subdivided into three classes according to their response to light wavelengths: short (blue-sensitive), medium (green-sensitive), and long (red-sensitive).
The fibers of approximately one million retinal ganglion cells form the optic nerve, the output from the retina. Optic nerve fibers terminate in the lateral geniculate nuclei (LGN), large bundles of cells lying in the thalamus beneath the cerebral cortex. LGN cells in turn project to the primary receiving area in the visual cortex. The two eyes’ fields of view overlap. Half the optic nerve fibers from each eye cross over to the opposite side of the brain (partial decussation). So each LGN receives input from both eyes but covers only half of the visual field. This arrangement means that binocular information from the right half of the visual field arrives in the left hemisphere via the left LGN (dotted lines in Figure 23.4), and binocular information from the left half of the visual field arrives in the right hemisphere via the right LGN (solid lines in Figure 23.4). After arrival in primary visual cortex (also known as striate cortex), signals are relayed to other cortical areas (known as extrastriate cortex).
Viewed as an information-processing system, the visual system can be broken down into a hierarchical series of processing stages. Signals arrive at each stage, are processed by a network of cells, and are then passed on to the next stage. Each cell in any one stage can itself be viewed as a processing device, taking inputs from the previous stage (and from other cells in the same stage) and sending output to the next stage (and to other cells in the same stage).
Figure 23.2c summarizes the main processing stages in the visual system. Each processing stage is represented by a box. The arrows connecting boxes show the main projection paths between stages; the width of each arrow represents the proportion of fibers in each cortical projection pathway. Most ganglion cells can be classified into one of three major types (midget, parasol, and bistratified), which project selectively to cells in the LGN (parvo, magno, and konio, respectively). Primary visual cortex (V1) is the starting point for cortical processing.
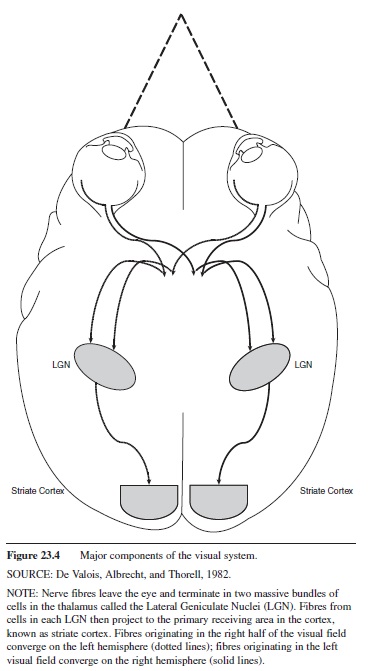 Figure 23.4 Major components of the visual system. SOURCE: De Valois, Albrecht, and Thorell, 1982.
Figure 23.4 Major components of the visual system. SOURCE: De Valois, Albrecht, and Thorell, 1982.
NOTE: Nerve fibres leave the eye and terminate in two massive bundles of cells in the thalamus called the Lateral Geniculate Nuclei (LGN). Fibres from cells in each LGN then project to the primary receiving area in the cortex, known as striate cortex. Fibres originating in the right half of the visual field converge on the left hemisphere (dotted lines); fibres originating in the left visual field converge on the right hemisphere (solid lines).
Beyond area V2, processing splits into two streams. The ventral stream contains the bulk of cells, and incorporates areas V4 and IT in temporal cortex; the smaller parietal stream includes areas V3, MT, and MST in parietal cortex. Lesion and brain-imaging studies indicate distinct roles for the two streams. Ventral lesions cause impairments in spatial form and color perception. Parietal lesions result in impaired motion direction and speed perception. Brain scans reveal hot spots of activity in ventral cortex, V1, and V2 using color stimuli, and hot spots in parietal cortex while viewing motion stimuli. According to one popular characterization of the different roles of the two streams, the ventral stream specializes in the analysis of color and form, or the “what” properties of the image, and the dorsal stream specializes in the analysis of motion and space, or the “where” properties. According to an alternative characterization, the ventral stream mediates conscious awareness of vision, whereas the dorsal stream mediates unconscious, visually guided action. There is currently no universal agreement on which of these two views offers the best way forward.
Neural Selectivity
Single-unit recordings show that cells in the visual system have a high degree of stimulus specificity. Each cell responds only when a visual stimulus is presented at a specific location on the retina, defining the cell’s receptive field. Furthermore, the stimulus must have certain characteristics in order to provoke a significant response from the cell. Stimulus preferences become more elaborate as one advances up the visual system.
Ganglion and LGN cell receptive fields are roughly circular, and most (midget/parvo and parasol/magno) have a center-surround organization; some cells are excited by light falling in the central region and inhibited by light in the surround; other cells have the opposite arrangement. Such spatial opponency means that the cell responds more strongly to patterns of light and dark than to even illumination falling across the entire receptive field. Most ganglion and LGN cells also have some degree of spectral opponency; they are excited by input from one part of the visible spectrum and inhibited by light from another part of the spectrum. Spectrally opponent cells fall into two classes: red versus green (midget/parvo) and blue versus yellow (bistratified/konio).
Receptive fields in visual cortex have more elaborate stimulus preferences. A minority of cortical cell receptive fields (so-called “simple” cells) have elongated, abutting excitatory and inhibitory regions, so the cell responds strongly only when an edge or bar of appropriate size lies at the optimal position and orientation in the receptive field. The majority of cortical cell receptive fields (so-called “complex” cells) do not contain inhibitory and excitatory zones but nevertheless are orientation-selective, so response depends on orientation and size but not position. Many of these cells also respond selectively to the direction of stimulus movement. Some cortical cells respond selectively to wavelength.

Functional Significance of Neural Selectivity
The information present in the visual image varies along five dimensions, as described in the introduction. Each stimulus-selective neuron can be viewed as taking a measurement or sample of the image at a particular location in this five-dimensional space, to provide raw data for later levels of processing. For example, the restricted retinal area of a given cell’s receptive field means that the cell measures the image at specific x and y locations, wavelength selectivity samples the wavelength dimension, and direction selectivity provides specific information about image variation over a specific region of space and time. Stimulus-specific neurons thus create a highly efficient representation of the information present in the multidimensional visual image.
Gain Control
Neural activity is metabolically expensive because it consumes energy. Furthermore, natural images have a high degree of statistical redundancy: They are highly predictable in the sense that information at a given location in space and time is likely to be highly correlated with information at a nearby location in space or time. Energy demands and redundancy can be minimized by allowing a given cell’s response level to adjust or adapt itself to the prevailing level of stimulation in nearby cells. The process of adjustment or adaptation is known as gain control. Neurophysiological studies have shown that the process is implemented by mutual inhibition between nearby cells in the visual cortex. For example, a given motion-selective cell inhibits its neighbors and is in turn inhibited by them. If all cells are highly active, then their responses are redundant. Mutual inhibition serves to reduce their response level or, in other words, to reduce their gain (the rate at which response increases with stimulus level).
Population Coding
Each cell in the visual system responds selectively to a constellation of stimulus attributes—in other words, a specific combination of the five dimensions in the retinal luminance function. But the cell can only offer a one-dimensional output value, its activity level. So it is impossible to deduce the particular mix of values along five dimensions that generated an individual cell’s response. For example, it is not possible to infer the orientation of a line in the image from the activity level of an individual orientation selective cell (or a group of cells sharing the same orientation selectivity). The cell’s response depends on stimulus size and contrast, and perhaps motion direction, as well as orientation. Stimulus orientation can be inferred by comparing the cell’s response level with responses in other cells tuned to different orientations.
Stimulus orientation can be inferred from the preference of the most active cells. This coding principle is known as population coding, since it is based on relative activity in a whole population of cells, rather than in single cells.
Psychophysics
Psychophysical research can reveal the functional properties of the visual system, allowing us to enumerate the processing modules involved in visual tasks and the computations performed by the modules. Although links with underlying neurophysiological structures are necessarily tentative, there is often a striking degree of correspondence between psychophysical data and neurophysiological data.
Low-Level Modular Measurement of the Retinal Luminance Function
Sensory adaptation experiments have been especially informative about the nature of low-level processing in human vision. An adaptation experiment involves three phases. In the first phase (preadaptation), the subject’s sensitivity is measured to a range of stimuli along some stimulus dimension, such as grating spatial frequency (a measure of bar width) or motion direction. In the second phase (adaptation), the subject is exposed to an intense stimulus at a specific location on the dimension, such as a specific grating frequency or motion direction. Finally, in the test phase (postadaptation), the subject’s sensitivity is measured to the same stimuli as used in the preadaptation phase. The difference between pre- and postadaptation sensitivity to each stimulus is taken as a measure of the effect of the adapting stimulus. Results typically show a drop in sensitivity or, in other words, elevated postadaptation thresholds compared to preadaptation thresholds. Modern explanations of the cause of the sensitivity drop link it to gain-control processes identified physiologically and described in the previous section. Crucially, threshold elevation is usually found only for stimuli close to the adaptation stimulus on the relevant stimulus dimension. For example, adaptation is localized to the retinal area exposed to the adapting stimulus and is found only for test stimuli close in spatial frequency, motion direction, and orientation.
Masking has also been used to study low-level visual processing. In this paradigm the subject is required to detect the presence of a target stimulus, such as a grating in the presence of an irrelevant “mask” stimulus. The presence of the mask interferes with performance, but only when the mask is close to the test stimulus along the relevant stimulus dimension. Masking can be explained by the idea that detection is mediated by stimulus selective channels; masks interfere with target detection only when the two stimuli are similar enough to stimulate the same channel.
Psychophysical adaptation and masking studies indicate that early visual processing is served by a bank of filters or channels that each respond to a narrow range of stimuli.
These channels send signals to specialized modules that extract information about motion, depth, and color.
Spatiotemporal Channels
Detection of spatial structure such as edges and bars appears to be mediated by a relatively small number of spatial frequency selective channels, perhaps as few as six or eight at any one retinal location. The temporal response of these channels can be examined by measuring observers’ sensitivity to flickering lights or gratings using an adaptation or masking paradigm. Results show that flicker detection is mediated by only two or three selective channels; some channels respond over time more quickly than others. Each channel can be described both in terms of its spatial response and its temporal response, namely its spatiotemporal response. So at any one retinal location there are perhaps 20 or 30 different spatiotemporal channels providing measurements of the local spatial and temporal structure of the image.
Channels identified psychophysically can be related to the stimulus-specific cells in the visual cortex. For example, Figure 23.5a shows the response selectivity of single cortical cells to grating frequency, obtained from single-cell recordings; Figure 23.5b shows the magnitude of threshold elevation at several different adapting frequencies, obtained psychophysically. The similarity is striking.
The properties of psychophysical channels and of cortical cells can be described quite well using Linear Systems theory. Each channel or cell acts as a linear filter that transmits some stimulus components relatively intact, but removes or filters out other components. Certain aspects of behavior are nonlinear, but these nonlinearities can be identified and accommodated within the Linear Systems framework.
Motion
An important function of spatiotemporal channels is to provide inputs to motion-sensing processes that signal stimulus direction and speed. Motion sensing is one of the most completely understood aspects of low-level visual processing, with sound, direct links between theory, neurophysiology, and psychophysics. Moving objects in the visual field generate patterns of light and dark that drift across the retina, occupying different positions at different times. So in theory, motion can be inferred by correlating two samples of the retinal image that are separated in space and time. A high correlation indicates the presence of motion in the direction of spatial and temporal offset between the sample locations. Well-defined mathematical limits can be placed on the degree to which the two samples can be separated before motion signals become unreliable. Early evidence for neural circuits that perform the necessary spatiotemporal correlation initially came from observations of beetles and flies, in classic experiments performed by Hassenstein and Reichardt in the 1950s. In physiological terms, the correlator proposed by Hassenstein and Reichardt consists of two cells with receptive fields separated by a short distance on the retina, which provide paired inputs to a third cell. The latter cell is the motion sensor. It responds only upon receiving simultaneous signals from the two inputs. One input cell has a faster temporal response than the other.
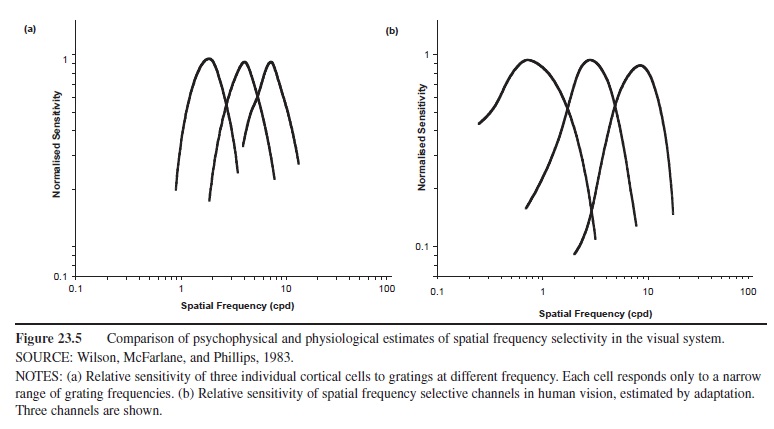 Figure 23.5 Comparison of psychophysical and physiological estimates of spatial frequency selectivity in the visual system. SOURCE: Wilson, McFarlane, and Phillips, 1983.
Figure 23.5 Comparison of psychophysical and physiological estimates of spatial frequency selectivity in the visual system. SOURCE: Wilson, McFarlane, and Phillips, 1983.
NOTES: (a) Relative sensitivity of three individual cortical cells to gratings at different frequency. Each cell responds only to a narrow range of grating frequencies. (b) Relative sensitivity of spatial frequency selective channels in human vision, estimated by adaptation. Three channels are shown.
If the difference in response speed matches the time taken for a moving stimulus to traverse the spatial interval between the two input receptive fields, the sensor’s response will be direction-selective. It will show a strong response when the stimulus moves in the direction from the slower input receptive field to the faster. Although the faster signal occurs later, by the time it arrives at the sensor it will have caught up with the earlier, slower signal. Movement in the direction from the faster input to the slower produces no response from the sensor because the two signals arrive at different times. In order to detect image motion at many different speeds and in many directions, the visual system must possess sensors with inputs having a range of spatial separations and temporal responses. Physiological studies of many animals, from insects to nonhuman primates, have offered support for the basic correlator theory of motion sensing. In humans, three lines of psychophysical evidence are consistent with the operation of motion-sensing neural circuits.
First, following adaptation to movement in one direction, a subsequently viewed stationary pattern will appear to move in the opposite direction, at least for a short time (the motion aftereffect, or MAE: a demonstration can be viewed at http://www.lifesci.sussex.ac.uk/home/George_ Mather/Motion/MAE.HTML). The effect can be explained by population coding of direction in direction-tuned motion sensors: Apparent movement is seen when some sensors respond more than others; adaptation to a given direction lowers the responsiveness of sensors tuned to that direction; and the resulting imbalance in sensor response simulates the pattern of activity that would normally occur in the presence of motion in the opposite direction. So a MAE is experienced.
Second, motion adaptation generates direction-specific threshold elevation. Adaptation to rightward motion, for example, reduces later sensitivity to rightward motion but not to leftward motion. Selective adaptation to direction is a strong indication that direction-tuned channels mediate detection of motion, as explained earlier.
The third line of evidence comes from studies of stroboscopic motion, in which moving patterns are briefly flashed in different spatial positions (as in cine film strips or in stop-frame animation). Stroboscopic motion can mediate realistic impressions of movement, as witnessed by the success of film and television. However, psychophysical studies have found that stroboscopic motion is effective only when the spatial and temporal intervals between animation frames are relatively short. Such short limits are indicative of the involvement of neural correlator circuits. Apparent motion is seen only when the spatial and temporal parameters of the animation match the spatial and temporal intervals built into neural correlators. Psychophysically identified limits on stroboscopic motion perception agree with predictions based on mathematical considerations of sampled motion, and with the properties of cells found in primate cortex.
Although motion sensors play a major role in modern theories of motion perception, they cannot explain all aspects of motion perception. A second, active mechanism is also required, in which motion perception is mediated by spatial shifts in focal attention.
Depth
Most animals have two eyes and receive two images of the world, one in each eye. Human eyes are separated horizontally in the head by an average distance of 6.3 cm. While viewing a natural, three-dimensional world, the small difference in viewpoint causes slight differences between the images received by the eyes. Both eyes face forward and, unless there is a disorder affecting the extraocular muscles, their optical axes converge to allow binocular fixation on a given point of interest in the visual field. The image of a second, nonfixated point in the visual field will be shifted horizontally in one eye’s image relative to the other eye’s image (horizontal binocular disparity) if that point lies at a difference distance from the viewer than the fixated point. Horizontal binocular disparity offers a precise, quantitative cue to depth. The sign and magnitude of disparity depends on how much nearer or farther away from the observer the nonfixated point lies relative to the fixated point. Disparity increases progressively as the difference between fixated and nonfixated distance increases, though most of the variation occurs within two meters of fixation distance. Random dot stereograms (RDS) were devised by Bela Julesz in the 1960s as a stimulus for studying the use of disparity as a depth cue for human vision. A RDS consists of two fields of random black-white dots, one presented to each eye. The pattern of dots in the two fields is identical, except for a region of dots in one field that is shifted horizontally relative to their position in the other field. The position shift creates horizontal disparity when the RDS is viewed in a stereoscope. Subjects can readily perceive the depth defined by the disparity, proving that disparity alone is a sufficient cue for depth perception. Single-unit recording studies have shown that a class of cells in the primate cortex is disparity selective, and corresponding cells in human cortex almost certainly mediate our ability to perceive depth from disparity. Each disparity selective cell must be binocular; it has a receptive field in each eye. Disparity selectivity can be created simply by shifting the horizontal retinal position of the receptive field in one eye relative to the other eye. Some cells prefer “near” disparity (the nonfixated point is nearer than the fixated point); other cells prefer “far” disparity (the nonfixated point is farther away than the fixated point); a third class of cells prefer zero disparity (the nonfixated point is at the same distance as the fixated point).
A number of other cues also offer information about depth in a viewed scene. A range of monocular visual cues is available (also known as pictorial cues), including blur, retinal size, height in the visual field, texture gradient, motion parallax, atmospheric perspective, and interposition:
- Blur. Due to the limited depth-of-focus of the eye, points nearer or farther away than the fixated point may appear blurred in the image. The same effect is seen in photographs.
- Retinal size. The size of an object’s image on the retina diminishes as you move farther away from the object.
- Height in the visual field. Objects lying nearby on the ground appear very low down in your field of view; more distant objects occupy higher positions in the image.
- Texture gradient. The width, height, and density of texture elements on a slanted surface all change progressively as your distance away from them increases.
- Motion parallax. The movement in one part of an image relative to another produced by movement through a three-dimensional world such as the relative motion seen from a train window.
- Atmospheric perspective. A reduction in contrast and change in color appearance for distant objects, due to the scattering effect of atmospheric particles such as dust and water.
- Interposition. The partial occlusion of one object by a nearer object.
In addition to a range of visual cues to depth, two nonvisual cues are also available from muscles inside or outside the eye:
- Accommodation. The shape of the eye’s lens must change in order to maintain a sharp image of fixated objects at different distances. Muscles inside the eye control lens shape and thus focusing power, so muscle state offers information about viewing distance.
- Vergence. The angle between the optical axes of the eyes must also change with viewing distance in order to maintain binocular fixation. The state of the extraocular muscles controlling vergence angle also provide information about viewing distance.
Most depth cues offer quantitative information about depth that is highly correlated across cues. Although there are many cues available, natural visual tasks such as picking up a teacup, catching a ball, or driving a car require only a single depth estimate for a given object. The object can only be in one place at a time, after all. How are the estimates from different cues combined? It seems that the visual system takes an average of the estimates from different cues, but it weights each cue’s contribution to the average. Some cues attract more weight than others. Weights seem to be determined by Bayesian statistics, described earlier. Cues that are more reliable and more likely to be correct are given more weight.
Color
As already indicated, human color vision is trichromatic—it is based on responses in three classes of cone photoreceptor distinguished by their different spectral responses: Short wavelength cones are sensitive to light in the blue region of the visible spectrum; medium wavelength cones are sensitive to light in the green region; and long wavelength cones are sensitive to light in the red region. Neurons in the retina, LGN, and cortex code the relative response of the different cone classes by pitting their responses against one another. A given cell may be excited by one cone class, or a combination of classes, and inhibited by a different class or combination of classes. Psychophysically, the crucial aspect of cone response for color appearance is cone excitation ratio—the relative activity across the three cone classes. If two stimuli evoke the same pattern of activity across the three classes, then they will appear identical in color even if the physical wavelengths they emit are different. Such stimuli are called metamers. For example, a surface emitting light at a single wavelength of 500 nm may appear green. A second surface emitting light at three wavelengths, 410, 600, and 640 nm, will appear identical in color because it will excite the three cone classes in the same ratio as the single 500 nm light.
Colors are strongly influenced by spatial and temporal context. A green patch surrounded by a red background looks more vivid and saturated than an identical patch surrounded by a neutral colour (color contrast); a neutral patch may appear greenish after the observer has adapted to a red patch for a short time beforehand (color adaptation). Context effects demonstrate that the color appearance of a surface is governed by a comparison of the cone excitation ratio it generates with the cone excitation ratio generated by its spatial or temporal context. The green patch on a red background looks vivid because its cone excitation ratio shows a greater preponderance of medium-wavelength activity than the excitation ratio generated by the background. A neutral patch appears green after adaptation to red because the reduction in long-wavelength responses due to adaptation biases the cone excitation ratio in favor of the complementary color, green.
Context effects play a vital role in color vision. Color is an unchanging, intrinsic property of an object and potentially useful for discrimination and identification. The distinction between medium- and long-wavelength cones is thought to have evolved to allow our ancestors to distinguish ripeness in fruit and subtle differences in edible leaves. However, the wavelengths given off a surface do not remain constant because they depend partially on the wavelength properties of the illuminating light. Light at midday, for instance, has a high proportion of blue wavelengths, whereas light near dusk contains more long wavelengths. Illumination affects the whole scene by a constant amount. Color contrast and adaptation processes remove constant illumination effects, helping to achieve a high degree of constancy in color appearance.
High-Level Visual Inferences And Active Vision
Low-level modules that encode spatiotemporal frequency, motion, depth, and color provide a piecemeal, localized representation of selected image attributes. Linear Systems Theory has been particularly useful in describing the operation of these modules. Yet surfaces and objects cover much larger areas of the image. The visual system must use grouping operations to build a representation of large-scale structures in the image. High-level grouping processes cannot operate on the basis of linear addition of all local representations. Instead, they require nonlinear interactions such as mutual facilitation and suppression, driven by assumptions about the properties of natural images. These interactions produce a selective representation of the shape and textural properties of surfaces and objects.
Gestalt Grouping
The earliest demonstrations of such interactions came from Koffka, Kohler, and Wertheimer, the Gestalt psychologists working in Germany in the early twentieth century. They argued that visual system has a propensity to impose certain perceptual groupings on spatial patterns, driven by a set of organizing principles. They saw the most basic principle as the minimum or simplicity principle; pattern elements will be grouped to create the simplest perceptual organization. Their demonstrations show that elements that are visually similar in shape, size, color, or motion and that are close together will be grouped into a perceptual unit. Later work in computational vision by David Marr made use of Gestalt grouping principles to partition the image into regions and shapes that signify the presence of surface and objects. The grouping principles essentially embody assumptions about the visual properties of surfaces and objects. Most objects are made of cohesive, opaque material. So image elements that are close together, or visually similar, or move cohesively, are likely to have originated from the same object. Perceptual grouping processes exploit this assumption.
At a physiological level, perceptual grouping can be implemented using long-range interactions between stimulus-selective neurons, or by reciprocal connections from higher-level processes down to lower-level processes, or both. Cells tuned to the same orientation, for example, whose receptive fields are collinear, may engage in mutual facilitation to reinforce their responses. Cells tuned to dissimilar orientations may mutually suppress each other.
Flexible Processing
Traditional information-processing systems such as computer programs operate passively. When an input is applied, it triggers a cascade of processing operations that culminates in the production of an output. The computations are predefined to work autonomously and automatically, always producing the same output for a given input. Early computational theories of vision operated in the same way, but recent advances acknowledge that this approach is too simple for human vision. There is considerable evidence that human visual processing is flexible and selective. One major source of flexibility in processing is attention. In the absence of attention, even large-scale changes in the visual world are difficult to detect. Attention is known to modulate the speed of detection and sensitivity to visual stimuli, as well as the depth of adaptation. Neurophysiological studies have found that neuronal responses to attended locations or stimuli are enhanced, while responses to unattended locations or stimuli are suppressed.
Some modern computational approaches favor a hybrid system containing both bottom-up processes, which are applied to the input passively and automatically, and a collection of active, selective processes called visual routines. These routines are triggered as and when required for specific tasks, and may include such operations as searching for or counting objects of a certain kind present in the scene.
Recognition
Object representations in the brain are essential for a multitude of everyday visual tasks. The daily routine of eating and drinking uses object representations in a variety of ways:
- For identifying an object as belonging to a particular class of objects, such as a glass
- For discriminating between objects within a class such as your own personal mug
- For interacting with objects such as filling a mug, or picking it up
All of these tasks require that a link be made between a particular visual image and a stored object representation. Objects vary in their intrinsic properties such as shape, size, and surface characteristics. Images of the same object can also vary due to extrinsic factors such as observer viewpoint, lighting direction, and environmental clutter. Theories of object recognition in the human visual system differ in terms of how they deal with extrinsic factors. View-independent theories, such as Marr and Nishihara’s theory and Biederman’s recognition-by-components theory, attempt to remove extrinsic factors, constructing representations that contain only an object’s intrinsic properties. Such theories create a structural description of each object, which is essentially a list of the object’s parts and how they link together. View-dependent theories, such as Ullman’s alignment theory and Edelman’s feature-space theory, incorporate viewpoint effects in the representation. In these theories the representation reflects the characteristics of the object as seen from a specific viewpoint, or small collection of viewpoints. Computational analyses underpin the main proposals of each type of theory, and there is some psychophysical support for each from object recognition experiments. However, neither class of theory can claim unequivocal support. Physiological studies are not definitive on this issue. Some cells in inferotemporal cortex show extreme selectivity for complex patterns such as faces. Their response is not affected by changes in size or location. Other cells respond to specific views of three-dimensional objects. This result does not necessarily favor view-dependent theories because some degree of view dependence would be predicted by both view-dependent and view-independent object recognition theories. According to view-independent theories, structural descriptions are much more readily extracted from some views than from other views.
It may be the case that the two classes of theory are not mutually exclusive. Both view-dependent and view-independent representations are constructed, and have different functions.
Summary
An image of the external world is formed in the eye. Patterns of neural activity triggered by the retinal image travel up the visual pathway from eye to brain, and lead to conscious visual experiences. The visual system and its subsystems can be viewed as information-processing devices; each takes an input, processes it, and produces an output. The system’s task is to extract meaningful information from the multidimensional retinal image about the shape, identity, and disposition of the objects in the visual scene. Our understanding of how the visual system achieves this goal has benefited from mathematical and computational analyses of the information available in visual images. Physiological studies show that during early processing stimulus-selective neurons create a highly efficient representation of the spatial and temporal structure in the visual image. Higher-order, more specialized populations of cells extract information about spatial detail, motion, depth, and color. Psychophysical data are consistent with a decomposition of the visual system into specialized modules dedicated to the analysis of specific image attributes. High-level processing achieves order and recognition by applying selective, flexible operations to low-level data that take advantage of assumptions about the characteristics of natural images.
References:
- De Valois, R., Albrecht, D., & Thorell, L. (1982). Spatial frequency selectivity of cells in macaque visual cortex. Vision Research, 22, 545-559.
- Hubel, D. H. (1988). Eye, brain, and vision. New York: Scientific American Library.
- Landy, M. S., & Movshon, A. J. (Eds.). (1991). Computational models of visual processing. Cambridge, MA: MIT Press.
- Marr, D. (1982). Vision. San Francisco: Freeman.
- Mather, G. (2006). Foundations of perception. New York: Psychology Press.
- Pasternak, T., Bisley, J. W., & Calkins, D. (2003). Visual information processing in the primate brain. In M. Gallagher & R. J. Nelson (Eds.), Handbook of psychology (Vol. 3, pp. 139-185). New York: Wiley.
- Treue, S. (2001). Neural correlates of attention in primate visual cortex. Trends in Neurosciences, 24, 295-300.
- Wandell, B. A. (1999). Computational neuroimaging of human visual cortex. Annual Review of Neuroscience, 22, 145-173.
- Wilson, H. R., McFarlane, D., & Phillips, G. (1983). Spatial frequency tuning of orientation selective units estimated by oblique masking. Vision Research, 23, 873-882.
- Yantis, S. (Ed.). (2001). Visual perception: Essential readings. Philadelphia: Psychology Press.
See also:
Free research papers are not written to satisfy your specific instructions. You can use our professional writing services to order a custom research paper on any topic and get your high quality paper at affordable price.
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality

{kind=link}